
??? 摘 要: 提出了一種基于可編程網絡處理器IXP2400和GP-CPU的NAT/NAPT" title="NAT/NAPT">NAT/NAPT的實現方案,設計并實現了基于Intel IXP2400和GP-CPU所組成的具有安全防火墻功能的NAT系統。針對該NAT系統進行了性能分析,它能夠支持六十多萬并發TCP/UDP的連接容量與全線速為2Gb/s以太網連接速率,有效提高了NAT/NAPT的操作速度,克服了傳統NAT實現方案中的性能瓶頸。
??? 關鍵詞: 網絡處理器; IXP2400; NAT; NAPT; 微引擎
?
??? 在現代通信網應用中,網絡地址轉換NAT(Network Address Translation)技術是IETF提出的有效解決IPv4面臨的網絡地址枯竭問題的方案之一,是為提高網絡地址利用率、緩解IPv4地址枯竭壓力而采取的一種有效策略。與此同時,為滿足互聯網絡對高性能與靈活性的要求,網絡處理器作為一種可編程的高速處理器應運而生,它是新興的下一代網絡設備的核心,它綜合了GP-CPU(通用處理器)的完全可編程特性和專用處理器ASIC(Application Specific Integrated Circuit)的高速處理能力的優點,有效地兼顧了網絡設備的功能靈活性和性能強大性。因此,不但提高了網絡服務的處理能力而且還具有高線速處理性能,從而能夠很靈活地適應網絡的各種業務性能要求[1]。
對于傳統的基于GP-CPU或ASIC的NAT處理復雜、負荷過重而造成的性能瓶頸,本文提出了一種基于IXP2400和GP-CPU的NAT系統的實現方案,成功地實現了基于有效的全局地址或用戶配置的飽和度來執行NAT模式(包括靜態NAT與動態NAT)與NAPT模式(Network Address Port Translation,網絡地址與端口轉換)的動態切換功能,最高效地實現了網絡地址復用,同時大大提高了NAT/NAPT的地址轉換能力,克服了傳統的NAT網絡應用方案中因數據幀頭處理時間過長所導致的難以保持在NPs上一定的線速問題。
1 網絡處理器IXP2400和NAT/NAPT的概述
1.1 網絡處理器IXP2400簡介
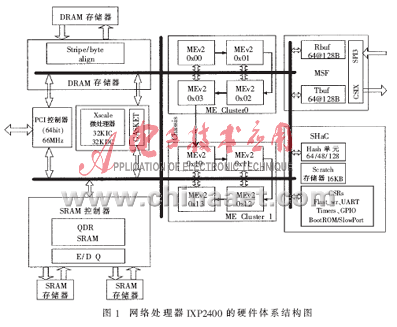
網絡處理器IXP2400是用來執行數據處理" title="數據處理">數據處理和轉發的高速可編程處理器,由一個Xscale Core(智能協處理單元,即32bit的嵌入式精簡指令集處理器)、8個微引擎" title="微引擎">微引擎Microengines(簡稱MEs),以及標準存儲接口單元和網絡接口單元等部分組成。IXP2400的硬件體系結構如圖1所示。IXP2400硬件體系結構的詳細描述主要來自于參考文獻[1]、[2]。
?
1.2 NAT/NAPT綜述
NAT具體可分為三種類型:靜態NAT、動態NAT和NAPT,分別用來支持IP地址轉換以及IP地址與TCP/UDP端口數據轉換。
NAT映射一個內部的IP地址到一個公網IP地址。當數據包穿過NAT時,不更換它的TCP/UDP端口號。NAT通常使用在一些具備公共IP地址池的NAT上,通過它可以進行地址綁定,即代表一臺內部主機。NAPT 則是一種動態地址轉換,它將一個由內部IP地址和TCP端口號組成的二元組映射到一個由外部IP地址和TCP端口號組成的二元組,從而允許多個內部IP地址共用一個合法外部IP地址[3]。二者都提供了一種機制:實現內網的IP地址與公網的IP地址之間的相互轉換,并將大量的內網IP地址轉換為一個或少量的公網合法的IP地址。因此,IP地址轉換的應用勢在必行。
2 基于IXP2400和GP-CPU的NAT系統的設計與實現
2.1 系統硬件的設計與實現
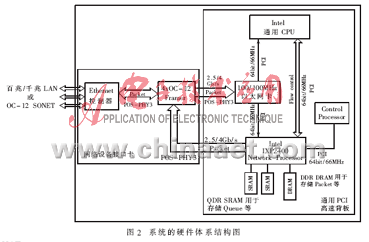
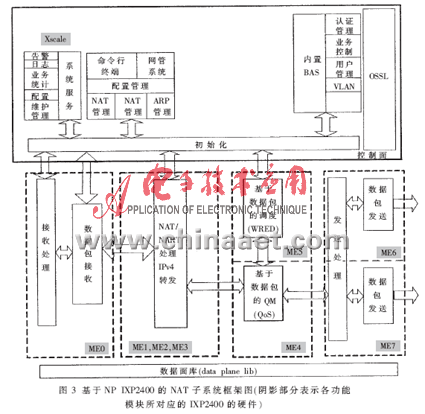
該系統設計的最終目標是要通過基于IXP2400和GP-CPU來實現具有安全防火墻功能的NAT/NAPT的應用方案。該系統的硬件體系結構如圖2所示,其中,基于NP IXP2400的NAT子系統是實現整個NAT系統核心功能的重要組成部分,也是整個NAT系統取得高性能的關鍵之所在,其結構圖如圖3所示。
?
?
?
該系統的實現平臺主要是由一片集成了時鐘頻率為600MHz的IXP2400的板卡、通用PCI高速背板、一片集成有GP-CPU的主板(即主機系統)、運行嵌入式VxWorks實時多任務操作系統、IDT公司的 PAX.Ware 2500i Media Interface Card、一個100/1000M以太網卡,以及Intel IXA SDK4.2[5]和相關的構建框架(Framework)等部件所組成。
基于IXP2400和GP-CPU的NAT系統能夠提供線速4Gb/s的以太網實現方案[6],并同時支持IPv4的單播轉發。作者通過編輯內核相關的代碼,使GP-CPU具有第二到四層數據包過濾功能;同時通過Intel IXA SDK4.2編輯相關的微代碼,并映射到NP IXP2400中創建一個NAT/NAPT功能模塊,從而實現具有安全防火墻功能的NAT系統的應用方案。
2.2 NAT子系統的軟件模塊設計與實現
基于NP IXP2400的NAT子系統的數據流程示意圖如圖4所示。作者把NP IXP2400的8個微引擎分別對應地分成具體的功能模塊: Packet RX模塊、NAT/NAPT處理和IPv4轉發功能模塊、Queue Manger模塊、Packet Scheduler模塊以及Packet TX模塊。在設計方案當中,接收、隊列管理及調度這三個功能模塊各占用一個微引擎,而數據包的發送模塊要占用兩個微引擎來發送數據包,其余三個微引擎用于NAT/NAPT和IPv4轉發的數據處理階段。在NAT/NAPT數據處理階段中,微引擎的分配使用是通過微引擎內部的指令執行周期與時延" title="時延">時延周期的數據分析來決定的,這一點將在2.3節中進一步說明。
?
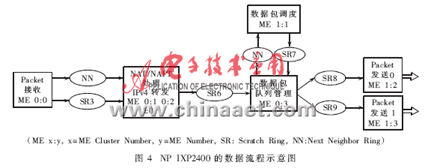
在NP IXP2400中NAT/NAPT的數據處理的詳細模塊,如圖5所示。 在Xscale Core(即控制面)與微引擎之間的通信過程中,有兩個Scratch Rings(SR0和SR1)按照優先排序的方式處理數據并控制數據包。作者所設計的NAT功能模塊既可以通過手動配置運行靜態NAT模式,同時也可以基于數據包運行動態NAT模式。
?
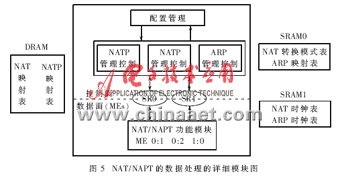
該NAT系統控制著NAT處理模式與NAPT處理模式的轉換,這種控制機理的實現是基于有效的全局地址或用戶配置的飽和度,確保內部網絡用戶對外部網絡不間斷的訪問,并能夠支持更多的網絡服務。所以,Xscale Core與 NAT/NAPT MEs(圖5)之間的通信是必不可少的,因為Xscale Core 管理控制著NBT(NAT/NAPT Binding Table,網絡地址/端口轉換映射表)而NAT/NAPT MEs 則是根據Xscale Core 所管控的 NBT 中所提供的信息來對數據包進行處理的。NAT子系統中NAT/NAPT模式的轉換是根據SRAM0中存儲的NAT轉換模式表來實現的,如圖5所示。在NAT子系統中運用這種模式轉換方案可把模式轉換帶來的數據傳輸中斷的影響降到了最低限。
2.3? NAT/NAPT功能模塊的微引擎分配
為了保持數據處理達到2Gb/s的全線速,NAT/NAPT功能模塊基于每個微引擎在處理數據包時,都要求在連續數據包的間隙內進行處理。筆者將NAT/NAPT模塊的功能映射到微引擎上來執行,是通過估算有效指令執行周期與I/O" title="I/O">I/O時延周期來實現的。在以太網接口層,最小的鏈路層數據幀的大小為84B(最小的以太網數據幀是64B,再加上幀間的數據幀頭是20B)。當線速為2Gb/s時,如果數據包的大小是84B,數據包的吞吐量將達到每秒鐘處理2.976M個數據包。其中,連續兩個84B的數據包的間隙為336ns。
PacketInterArrivalTime(ns)=PacketSize(Bytes)×8/DataRate(Gb/s)
上式中的幀間間隙可以被設置成子系統中處理器的時鐘,并由下列公式推導得出。由于NAT子系統是基于IXP2400來實現的,而IXP2400的時鐘頻率為600MHz,因此,該處理器的時鐘應為1.67ns。
PacketArrivalTime(ProcessorCycles)=PacketInterArrivalTime(ns)/ProcessorClockTick(ns)
所以,整個數據處理流程(如圖4所示)中的任何一個處理進程都必須能夠在特定周期(符合這種周期算法)內完成所要求的所有接收到的數據包的處理,而且,每個處理進程都應該能夠達到每202個周期處理一個新的數據包的處理速度,以支持2.0Gb/s的全線速。
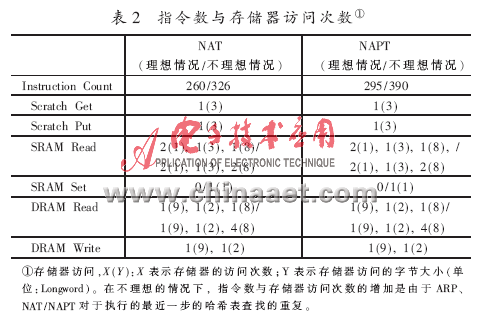
微引擎對數據包的處理包括:對內存儲器和外存儲器的訪問,例如:Scratch Memory、SRAM、DRAM等。訪問存儲器的時延與相鄰數據包之間的間隙是近似的,例如:SRAM存儲器的訪問時延大約是150 Cycles,而DRAM存儲器的訪問時延大約是250~300 Cycles[7]。每個微引擎內部有8個硬件線程(Context),采用多線程交換(Multi-Threading)技術時,由相應的硬件結構提供支持,由軟件指令來控制,可以將存儲器的訪問時延隱藏在指令執行周期的后面,因此,提供一個I/O時延周期相當于數據包傳輸速率的8倍,即一個I/O時延周期總計為8×202=1 616 Cycles(即8倍的以太網傳輸模式上的IPv4數據包最短到達時間),這樣充分發揮了微引擎的MIPS性能,提高了系統的并行處理能力。表1展示了不同的NAT/NAPT功能模塊中的微引擎數量組合(1ME、2MEs、3MEs)所對應的有效指令執行周期與I/O時延周期的值的變化。如果使用兩個微引擎執行NAT/NAPT處理,則上述兩種周期的值要比只有一個微引擎處理時增加兩倍,因為兩個MEs具有16個硬件線程,這樣可以并行處理16路數據包。表2展示了估算的指令執行次數和NAT/NAPT功能模塊中存儲器訪問的次數。在不理想的情況下,根據每個存儲器訪問類型[7]的時延的數值計算得出,執行NAPT處理時的I/O時延周期大約為2 880 Cycles。 因此,單個微引擎的指令執行周期與I/O時延周期要小于兩個微引擎的指令執行周期與I/O時延周期。所以,筆者設計此NAT/NAPT處理和IPv4轉發功能模塊應當配置三個微引擎并行工作,來支持網絡所要求的數據處理速度。這一分析結果將在下節的軟件仿真測試中被證實。

?
3? NAT系統的性能分析
這項仿真測試運用了IXP2400 Developer Workbench專用軟件開發平臺,通過編譯微代碼來實現數據的仿真。在測試當中,Workbench編譯器使用的參數設置都是默認值。
3.1 最大連接速率/最大會話速率
該性能測試為系統的TCP會話處理性能和峰值速率性能的測試集合。在性能測試之前,ARP的映射條目與NAT/NAPT的轉換條目采用動態配置的形式,關于最大連接速率與最大會話速率的測試:是通過固定的數據幀長度(84B)與60個客戶機和一個服務器來完成的。這項測試結果表明了所設計的NAT系統完全能夠以全線速處理數據包。
3.2? 平均轉發速率
在這項仿真測試過程中,當所有數據包的NMT查找采用一次地址沖突量(N-depth)匹配的方式時,以最小長度64B以太網幀生成于每個網絡地址,而且NBTs 的查找模式以N-depth匹配方式被靜態設置,所有的數據包都匯成一股數據流,執行NAT/NAPT處理的微引擎中的每個線程都會同時去訪問NMT,這樣就會引起DRAM存儲器訪問的沖突。當哈希沖突的次數不斷增加時,DRAM存儲器的負擔就會增大而且DRAM存儲器的訪問時延也會大大增加,再加上等待數據讀入線程的開銷,執行NAT/NAPT處理的微引擎中線程將會產生過度的時延。圖中曲線的走勢說明:隨著NBT查找匹配的一次地址沖突量的增加,將會導致平均轉發速率逐漸地降低。
3.3 時延分析
將本NAT系統(包含:子系統中的NAT/NAPT功能模塊)的時延與不具有NAT/NAPT功能僅僅只提供簡單的數據包轉發功能的系統的時延進行了對比。在對NAT系統的測試當中,ARP的映射條目與NAT/NAPT的轉換條目采用靜態配置的形式。通過對兩個不同的系統的性能仿真測試結果進行對比,得出以下結論:①與不具有NAT/NAPT功能的系統的時延相比,具有NAT/NAPT功能的系統的時延要增加6%~30%。②時延的平均增長比率是根據數據包的大小的不同而變化的,也就是說,如果數據包的大小在64B~256B范圍內,其時延的平均增長比率為25%;如果數據包的大小在512B~1 518B范圍內,其時延的平均增長比率為9%。以上測試結果表明:基于NP的NAT/NAPT功能模塊需要對數據包頭進行深度地處理。
NAT技術,對于當前的IPv4網絡中的地址耗盡和路由表的規模擴大是一個很有效的解決方案,因為網絡擴大時它需要很少的改變,并能很快地實現地址復用。作者設計出一種基于IXP2400和GP-CPU的NAT系統實現方案,成功地實現了地址復用,并且微引擎的多線程交換技術與并行處理能力有效地提高了系統的NAT/NAPT模塊數據處理的性能,解決了傳統NAT實現方案中的性能瓶頸。
在未來的工作計劃中,作者為了減少系統數據處理產生的哈希沖突次數,計劃創建一個新的哈希函數來減少哈希沖突,還要重新設計哈希表的數據結構來提高存儲器的利用率,最小化存儲器的訪問時延。
參考文獻
[1]?Intel. Intel IXP2400 Network Processor Hardware Reference Manual [M/CD] . USA: Intel Corporation, Oct.2004. [2] ?張宏科,蘇偉,武勇. 網絡處理器原理與技術[M].北京:北京郵電大學出版社,2004,11:18~138.
[3]? STEVENS R W. TCP/IP Illustrated, Volume 2: The Implementation[M].? Beijing: China Machine Press,April.2000: ?63-560.
[4]? Integrated Device Technology.? IDTTM PAX.wareTM 2500i?Evaluation System. 2004.
[5]? Intel. IXP2400 and IXP2800 Network Processor: Programmer’s Reference Manual[M/CD]. USA: Intel Corpora-
?tion, Jan. 2005.
[6] ?Intel. Internet Exchange Architecture Software Building?Blocks Reference Manual [M/CD]. USA: Intel Corporation, ?Feb. 2003.
[7]? LAKSHMANAMURTHY S, LIU K, PUN Y, et al.Network?Processor Performance Analysis Methodology[J]. USA:Intel ??Technology Journal, Aug. 2002,6(3):19-28.