
??? 摘 要:提出一種基于H.264的上下文自適應二進制算術編碼器硬件設計方法。本設計中包含一個由二進制化" title="二進制化">二進制化以及上下文模型組成的14組并行上下文對產生器,一個抓取鄰近區塊數據的三級流水線結構以及一個內含前饋處理且融合三種模式的四級流水線結構的算術編碼器。該算術編碼器可以一個時鐘處理一個位元" title="位元">位元;整個設計平均每個時鐘處理0.77個位元。
??? 關鍵詞:上下文自適應? CABAC? H.264/AVC? 語法元素
?
??? 視頻編碼的最后一步是熵編碼" title="熵編碼">熵編碼,主要應用在對量化變換系數、自適應塊變換、運動向量和其他編碼信息的壓縮技術中。H.264/AVC[1]采用兩種類型的熵編碼,基于上下文自適應的二進制算術編碼(CABAC)和基于上下文自適應的可變長編碼(CAVLC)。而CABAC[2]是一種比任何傳統熵編碼效率都要高的編碼法,與CAVLC相比,CABAC能節省6%~15%的位速率。在對CABAC算法分析的基礎上,筆者提出一種三級流水線結構實現方法,該方法充分利用高效的并行結構優化CABAC編碼器結構。
1 CABAC編碼器結構
??? 如圖1所示,結構由三大模塊構成:二進制化與上下文模型(CM)模塊,算數編碼(AE)模塊,并進串出(PISO)模塊。二進制化與上下文模型模塊負責產生二進制串及上下文建模[3],其輸出為并行的14組上下文對。CM模塊中的取鄰模塊通過取鄰地址產生器(AG)生成的地址,從取鄰存儲器中讀取出相鄰左宏塊" title="宏塊">宏塊和上宏塊中的語法元素(SE)。PISO模塊負責收集有效的上下文對,在一個時鐘周期" title="時鐘周期">時鐘周期中將其輸出到AE中。PISO模塊輸入為14組并行上下文對,輸出為一組上下文對。AE模塊[4]由融合三種模式的四級流水線構成,模塊中的表存儲器存儲初始語法表,片段初始化上下文表子模塊負責上下文表的建立。transIdxLPS表和rangeTabLPS表由組合邏輯電路實現,其中上下文表存儲器為雙端口存儲器。本編碼器編碼開始一段新片段編碼時,主控制器首先聲明start_slice_cabac寄存器,編碼器開始建造上下文表,當其完成后編碼器向主控制器發送聲明信號end_cabac_build_table,并且等待下一命令。這時編碼器開始新宏塊編碼,并分別從取鄰存儲器讀取相鄰區塊數據和從mb_info存儲中讀取宏塊SE數據。所有宏塊SE數據編碼完成后,CABAC編碼器開始從coeff_mem存儲器中讀取殘余SE。每完成一個宏塊,編碼器聲明一個end_mb寄存器,當前片段的最后一宏塊處理后,編碼器則聲明一個end_slice_cabac寄存器。
????????????????? 
??? 下面分別敘述編碼器的CM模塊和AE模塊。
1.1 二進制化與上下文模型模塊(CM)
??? 當前的語法元素通過該模塊二進制化,并為每一個二進制串(bin)計算相應的上下文,得到最小的冗余碼,如圖2所示。首先在一個時鐘內完成SE的二進制轉換,產生1~14的二進制串,為提高速度使用不查表法;然后根據先前的上區塊和左區塊編碼數據為bin,計算相應的上下文值;最后產生1~14組上下文對。每一組上下文對包括1bit編碼位,9bit上下文存儲地址位及2bit編碼模式位。
???????????????????? 
??? CABAC編碼器需要從相鄰的左區塊、上區塊及當前宏區塊中提取數據計算上下文值。圖3中取鄰模塊由3個緩沖寄存器構成,編碼時編碼器將當前被編碼的SE寫入當前宏區塊(MB)緩沖寄存器中,同時將左/上區塊數據從取鄰存儲器中取出,預載入之前MB緩沖寄存器1和2中。
??????????????? 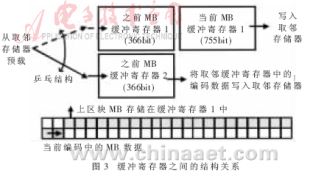
??? 當編碼MB是奇數地址時,編碼器從取鄰存儲器中取出左/上區塊SE,預載入之前MB緩沖寄存器1中,同時將當前宏區塊MB緩沖寄存器中被編碼的SE 寫入取鄰存儲器中。該模塊可以將之前MB緩沖寄存器2中的相鄰上區塊數據和當前宏區塊MB緩沖寄存器中的相鄰左區塊數據輸出到二進制化與上下文模型模塊中計算上下文對的值。
??? 相反,當編碼MB是偶數地址時,編碼器從取鄰存儲器中取出左/上區塊SE預載入之前MB緩沖寄存器2中,同時將當前宏區塊MB緩沖寄存器中被編碼的SE 寫入取鄰存儲器中。二進制化與上下文模型模塊可以從之前MB緩沖寄存器1和當前宏區塊MB緩沖寄存器中獲得相鄰塊數據。
1.2 算術編碼器模塊(AE)
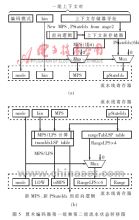
??? 這里提出一種融合3種模式(EncodeRegular,EncodeBypass和EncodeTerminal)的四級流水線結構的算術編碼器,如圖4。在第一級流水線中,編碼器從上下文表存儲器中讀出MPS和pStateIdx;在第二級中,編碼器判定bin是否是MPS并且讀取兩組合電路表(rangeTabLPS表和transIdxLPS表),得到新的MPS和pStateIdx;在第三級,編碼器計算出新的Range和Low;最后在第四級輸出編碼。同時其內饋前向邏輯更新上下文存儲器。
??????????????? 
??? (1)對于整數算數編碼,每編碼一次后對Range和Low的值都需要再歸一化。 經分析,EncodeRegular中儲存器訪問較耗時,決定由單獨一級流水從上下文表儲存器中讀取數據,并令再歸一化前沒完成的功能函數都集中到第二級流水階段完成。圖5(a)描述第一級流水線利用上下文存儲器地址讀取上下文存儲器。EncodeRegular時MPS和pStateIdx分別被存儲在流水線兩個寄存器中。而EncodeBypass和EncodeTerminal時,這兩個寄存器被置零,并且在第二級流水中暫不使用,二進制串和編碼模式位不做任何修改直接送入下級流水。圖5(b)為第二級流水結構。這里使用bin、MPS和pStateIdx來決定二進制串是否是MPS,并把得到的MPS傳送到寄存器“isMPS”中,為第三級流水做準備。此級也使用pStageIdx作為索引在rangeTabLPS表中搜索得到4個RangeLPS,并將結果儲存到流水線寄存器中。因為EncodeBypass和EncodeTerminal比較簡單,把它們主要集中到第一級和第二級中處理。另外,第二級中計算得到的新MPS和新pStatIdx將輸入到前向邏輯中,作為后續上下文起始判斷條件。
?????????????? ???? 
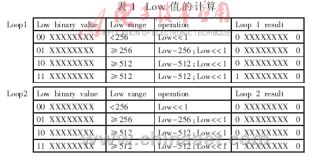
??? (2)為了得到期望的精確輸出,每編碼一次后對Range和Low的值都需要再歸一化。在H.264的CABAC中需要9bit和10bit分別表示Range和Low。Range值將逐漸變小,因此Range值限定在256~511之間。如果Range值小于256(0x100),Range將再歸一化,并緊接再歸一化Low。設計PutBit和bitsOutstanding位在第四級進行更新完成重整和輸出工作。根據對Range的判斷可以得到循環(loop)次數。最大的loop次數是8次。這里對Range和Low的更新要求在一個時鐘周期完成,因此設計每循環一次,Range/Low移位一次。
??? 表1描述經過loop1和loop2后的新Low值。根據第一次循環的結果,可以算出:僅僅當源流串的頭兩位都為1時,loop1結果的第一位才為1。loop2使用loop1的結果。這就意味:如果loop1結果的頭兩位都為1,loop2結果的第一位也為1。因此根據循環次數就可以判定Low的第一位比特和其余位。如果源流串的前(loop count+1)位都為1,新Low的第一位也將是1;否則,第一位將是0。通過使用這種方法,新Low可以在一個時鐘周期計算出來。
???????????????? 
??? 在第三級流水結構中,主要完成Range和Low的更新和邏輯反饋。源流串中的old_Low值及與循環次數有關的shift值都被寫入第四級流水線寄存器中,實現PutBit過程。圖6(a)為第三級流水,其左框架結構中為EncodeBypass和EncodeTerminal模式的簡單運算得到新Low。右框架結構為EncodeRegular有關MPS和LPS的一些簡單運算,然后通過normalization shift更新Range和Low值。
???????????????????? 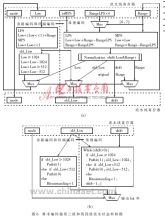
??? 第四級流水結構主要實現bit流的輸出過程。圖6(b)為第四級流水,其左框架結構中為EncodeBypass和EncodeTerminal bit流輸出,再歸一化后根據old_Low決定下一個輸出bit為0或1。右框架結構為EncodeRegular輸出。首先判斷shift值是否大于0,如大于0,再根據old_Low決定下一個輸出bit為0或1,同時改變old_Low值。分兩種情況:(1)如果old_Low前兩位的值為00,10或11時可以直接輸出,然后丟棄Low第一位;(2)如果old_Low前兩位的值為01,將不能直接輸出bit。使用bitsOutstanding寄存器來計算這種情況的連續出現次數。再根據PutBit(B)決定輸出位。每一次運算shift值減1,重復運算直至shift值小于0。
2 試驗及結果分析
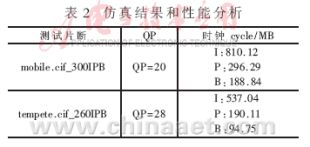
??? 對上述的CABAC編碼器用Verilog HDL[5]硬件設計語言進行設計,在NC-Vrerilog仿真器上進行仿真實驗,對H.264/AVC測試序列視頻流編碼測試,并與JVT校驗模型JM9.6[6]的編碼結果進行比較,表明該CABAC編碼器可以滿足實時編碼的要求,且表現出色。這里使用了兩個ISO/IEC標準視頻測試片斷“Mobile”和“Tempete”對CABAC進行測試,仿真和性能分析結果見表2、表3。
?????????????????? 
????????????????????
??? 平均計算,AE耗時190個時鐘編碼P-slice宏塊,同時耗時543個時鐘編碼I-slice宏塊。換句話說:該算術編碼器可以一個時鐘處理一個位元;而且整個設計可以平均每個時鐘處理0.77個位元。
??? 對于上述設計,采用ALTERA公司的QUARTUSII5.0開發軟件,表4給出了具體的實現參數。
??????????????????? 
??? 本文提出一種高效的CABAC編碼器硬件實現結構。在對H.264/AVC語法表和CABAC算法深入分析的基礎上設計一種內含前饋邏輯電路三模四級流水結構算術編碼器。該編碼器可以一個時鐘處理一個位元;整個設計綜合計算平均每個時鐘處理0.77個位元。但這并不是最優設計,下一步將去除取鄰模塊的緩沖器來減少功耗和面積,并且采用重載1-2系數的方式減少系數編碼的時鐘周期。
參考文獻
[1] Draft ITU-T Recommendation and final?draft international standard of joint video specification(ITU-T Rec.H.264|ISO/IEC 14496-10 AVC).
[2] MARPE D,SCHWARZ H,WIEGAND T.Context-based adaptive binary arithmetic???? coding in the H.264/AVC video compression standard.IEEE Transactions on?? Circuits and Systems for Video Technology,2003,(7).
[3] OSORIO R R,BRUGUERA J D.A new?architecture for fast arithmetic coding in H.264?advanced video coder.Euromicro symposium on?digital system design,2005.
[4] SHOJANIA H,SUDHARSANAN S.A high performance CABAC encoder.IEEE 2005 The 3rd?
International IEEE-NEWCAS Conference,2005.
[5] IEEE standard hardware description language?based on the verilog hardware description language(IEEE Std p1364-2001).
[6] JVT H.264/AVC Reference Software JM 9.6