
??? 摘 要: 在VOIP應用的基礎上,介紹了VOIP的現狀及其用于VOIP語音編碼" title="語音編碼">語音編碼標準的發展方向,并對VOIP網路通信語音編碼標準之一的G.729 A[1]進行了優化改進,提出了一種利用重新初始化來獲得狀態恢復(RbR)與WD-LSP[8](Weighted delta-LSP)相結合的CS-ACELP語音編碼算法,利用重新初始化來獲得狀態恢復,解決了包丟失階段和在包丟失以后階段產生差錯脈沖所引起的重建語音質量" title="語音質量">語音質量下降問題的同時,采用WD-LSP降低了算法復雜度" title="算法復雜度">算法復雜度。
??? 關鍵詞: G.729A? WD-LSP? CS-ACELP? RbR
?
???? VOIP是近年來快速發展起來的一項新的網絡通信技術,已在全世界得到了廣泛應用。然而受網絡傳輸帶寬、傳輸速率和網絡環境等因素的制約,目前網絡電話在語音質量和傳輸延時方面還有待完善。低速率語音編解碼" title="編解碼">編解碼技術是IP網絡多媒體通信中最關鍵的技術之一。有低速率語音壓縮編解碼技術的基礎上,結合網絡通信技術,提出了一種高效的語音實時通信方案。
1 編解碼方案的選擇
??? 壓縮和解壓縮方案的選擇需要考慮語音質量、速度、復雜度、延時四個方面。IP 語音通信主要使用ITU定義的幾個語音編碼的標準:G.723.1、G.728和G.929。G.729A是ITU推出的用于第四代語音編碼標準,采用了共軛結構-算術碼本激勵線性預測編碼(CS-ACELP)算法。
2 VOIP語音編碼改進中的關鍵技術
??? VOIP中語音編碼或稱語音壓縮編碼研究的基本問題主要包括:(1)在給定編碼速率的條件下如何得到盡量好的重建語音質量,或稱編碼質量。同時應盡量減小編解碼時延以及算法的復雜度。(2)由于語音在網絡傳輸使用UDP的協議,對在傳輸過程中出現錯誤或丟失采用的幀檢錯糾錯和丟失補償處理,以保證更好的語音質量,因此對整個 G.729A聲碼器的改進也是針對上述兩個方面進行的。
3 RbR與WD-LSP[8]相結合的CS-ACELP語音編碼算法
3.1 WD-LSP在G.729A中的應用
??? G.729A編碼器中功能模塊的改進重點在于自適應碼本搜索,因為它們占用了聲碼器大部分的處理時間。這包括自適應碼本矢量的產生、自適應碼本時延的碼字編碼、自適應碼本增益的計算、固定碼本搜索、固定碼本矢量的產生、固定碼本的碼字編碼、固定碼本增益的量化。同時與自適應碼本搜索相關的開環基音分析也有改進的余地。本文采用一種新的降低算法復雜度的方法,即結合WD-LSP(Weighted delta-LSP)采用次最優部分碼本快速搜索的CS-ACELP 語音編碼算法[3],其原理圖如圖1所示。
???????????????????????? 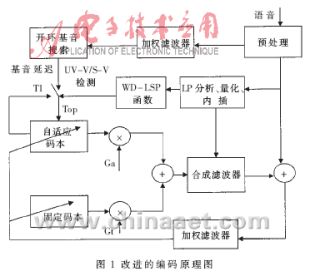
??? 在G.729A語音編碼階段,為了減少搜索最佳自適應碼本延遲必需的計算量,開環基音延遲Top在每幀(10ms)都作一次分析,因而需要較多的CPU時間用于開環基音分析。因此可采用WD-LSP函數來減少用于開環基音分析的計算量。WD-LSP函數主要用于區分UV-V(unvoice-voice)/S-V(silence-voice)的邊界。其原理是:如果函數值大于給定的極限值η,則開環基音延遲Top重新估計,否則,Top用前一幀的自適應碼本延遲來更新。在第i幀Fi的WD-LSP函數和用于確定Top的算法描述如下:
??? 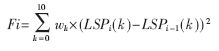
??? 如果Fi>η,重新估計Top
??? 另外Top=自適應碼本延遲
??? 其中LSPi(k)是在第i幀中的k階LSP系數;wk是加權系數,它用于增強UV-V/S-V邊界的WD-LSP函數。為了獲取wk,一個包含23 014個UV-V邊界和9 519個S-V邊界的大型數據庫用于估計delta-LSP在UV-V/S-V邊界的平方根值(RMS)。因此,WD-LSP用于檢測VU-V/S-V邊界非常敏感。η是一個設為0.01的極限值。整個計算可節省21%的計算量,且合成語音質量仍然較好。
3.2 RbR改善包丟失所引起的語音質量
??? 由于G.729A具有15ms的低算法延遲[8]和丟失包的恢復機制,因此G.729A應用于VOIP是一種很好的選擇。G.729A把語音分為每10ms為一幀,同時每一幀再被分為兩個5ms的子幀。需要傳輸的參數以每幀80bit進行傳輸,因此導致要求8kbps的數據傳輸率。
??? 語音傳輸過程中,在包丟失階段和在包丟失以后的一個階段都會產生差錯脈沖。跟在包丟失后面的差錯稱為狀態錯誤,這些錯誤都可以被耳朵察覺到從而會明顯地降低語音的質量。
??? 包丟失后一段延時內有錯誤,原因就是在包丟失的一個階段編碼器與解碼器的狀態不能夠再同步。在本文中用于狀態的所有存儲器都在編碼器和解碼器中不會相互交換,但是會進行經常的更新以保證它們在兩邊相同。編碼器產生以系列的參數來模擬基于當前狀態的語音。這些參數傳輸到解碼器再由這些參數和本地的狀態來重新產生語音。在正規操作下,編碼器和解碼器的狀態不斷更新以保持相同,從而使解碼器重新合成原始語音。但是在包丟失階段,因為接收者不能完全對狀態進行更新,因此編碼器與解碼器不再同步。即使之后沒有數據包丟失,正確接收數據包時,解碼器用錯誤的狀態來重新產生語音,無疑會導致明顯的語音失真。本文所定義的G.729A算法的狀態如表1所示。這是通過分析和基于文獻[5]確定的。
???????????????????????????? 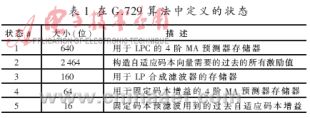
??? 在大量仿真的基礎上,可以注意到在狀態#1、#4和#5重新同步以前,該算法分別采用4幀、2幀和1幀。而狀態#2和#3是基于過去的輸出,所以對于這些狀態所采用的幀的數量是變化的,并且隨著包丟失發生的位置而變化。仿真表明:在上一幀為幀擦除的情況下,對應于狀態#2和#3分別以32幀和30幀來獲得重新的同步。這些結果顯示在一幀丟失后,所有的狀態獲得重新同步平均需要32幀。然而,也應該注意到,在包丟失后語音質量下降不會持續很長時間。
??? 另外做了一個測試來核實哪種狀態對語音質量的下降影響最大。修改算法,以便在需要進行幀的數據擦除時獨立地對值進行修改,而不需要擦除一幀的數據。結果表明#2狀態無疑是引起語音下降的主要狀態,同時在當同步喪失時對狀態錯誤的影響最大。
??? 在G.729A中,對包丟失發生時有很好的應對處理方法,但是對于因包丟失引起的狀態錯誤沒能得到好的恢復。在G.729A中采用了一種新的方法來提高在包丟失期間自錯誤狀態的恢復情況。
??? 對于一個給定的狀態,解碼器產生了與這個狀態相對應的一系列最佳的語音壓縮參數。然而壓縮質量無疑依賴于狀態的最佳性,在包丟失發生后差錯發生的主要原因是狀態和壓縮參數的不匹配。
??? 基于上面的討論,建議當發生包丟失時,通過每N幀在編碼器和解碼器兩端對狀態#2進行周期性的歸零初始化來維持解碼器和編碼器的匹配。這種通過重新初始化來獲得恢復的方法具有簡單性同時保證了在包丟失時減少了狀態差錯的數量。
??? 通過試驗發現,為了獲得更好的結果必須對所描述的關于執行RbR的技術進行修改。這是由于對其進行初始化的幀以及跟隨此幀的下一幀比未進行初始化的幀對于包丟失更敏感。為了補償這種情況,試驗表明最有效的方式是增加冗余信息" title="冗余信息">冗余信息。如果對其進行初始化的幀為幀#n,那么解決的方法就是將幀#n的增益值和固定碼本向量與幀#n+1一起傳輸。同樣的,將#n+1幀的基音值和增益與幀#n+2一起傳送。無論包丟失發生在幀#n+1還是幀#n+2,都可以用冗余信息來減少包丟失的影響。每個初始化間隔冗余信息需要76bit,從而去除了這些幀對于幀丟失的額外的敏感度。對于N=10的初始化間隔,RbR需要8.76kbps(大約9.5%的冗余)。
3.3 試驗結果
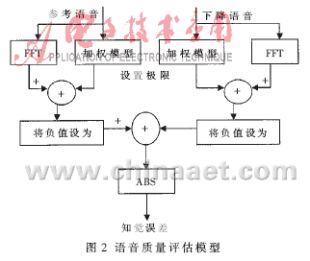
??? 為了評價RbR的性能,需要一個合適的方法來評價語音質量。因為人耳的特性,并不是所有的誤差都能被察覺,這取決于作為語音質量的指標的平方誤差的數值。為了客觀地評價語音質量,采用了圖2所示的系統。這個系統用一個知覺模型來計算兩個語音文件的聽覺差,這個知覺模型類似于MPEG聲頻壓縮的模型[6]。這個誤差是所有語音幀的總和除以采樣的數量來獲得每個采樣的知覺誤差(PEpS)。這種方法被證明是檢測語音質量的一種很好的指標。
?????????????????? 
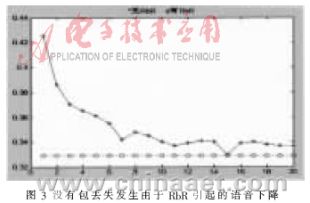
??? 需要考慮的首要問題是證明當未發生幀擦除時,RbR是否會對語音產生影響。這是因為傳輸者沒有辦法預知包丟失是否發生,而在未發生包丟失時也要進行RbR操作。對應于不同初始化間隔的進行RbR操作的PEpS和未進行RbR操作的PEpS的比較如圖3所示。可以看到,當初始化間隔N的選取大于9時其降低不明顯。如果N進一步減小,其質量將會降低從而使得輸出語音變為噪聲。測試將狀態#2設置為0的影響,因為需要內插狀態#2的數值,因此自適應碼本向量為0。在這種情況下,所有的激勵都是由用于無聲語音的固定碼本向量組成。如果語音為有聲語音,則編碼器以分析-合成的特性來選取最佳的固定碼本向量,因此可以使原始語音與合成語音之間的知覺誤差最小,從而使下降度維持在最小。同樣,自適應前向濾波器用于對所有固定碼本向量進行濾波也可以減少下降度的影響,這是因為它增加了一些有聲元素到固定碼本向量中。這也能達到筆者所期望的狀態,即如果RbR不是進行經常操作,則在未發生包丟失的階段由RbR引起的下降度不明顯。
???????????????????????????? 
??? 本文就提高重建語音的音質與降低算法復雜度方面,針對G.729A目前的現狀,提出了利用重新初始化來獲得狀態恢復(RbR)與WD-LSP(Weighted delta-LSP)相結合的CS-ACELP 語音編碼算法,解決了目前網絡通信由于帶寬和包丟失帶來的問題,保證了語音的質量。對今后G.729A語音編碼的發展改進以及在VOIP中的應用具有一定的意義。
參考文獻
[1] ITU-T Recommendation G.729 Annex A[S].
[2] HWANG Shaw-Hwa. Computional improvement for G.729?standard[J]. ELECTRONIC LETTERS.22nd June 2000:
?1163-1164.
[3]?ITU-T G.729: Coding of speech at 8kb/s using conjugat-estructure algebraic-code excited linear-prediction(CSACELP).International Telecommunications Union, March1996.
[4]?楊國芳,高飛.一種基于G[1].729的CS-ACELP新算法[J].語音技術,2004,(1):56-59.
[5] ROSENBERG J. G.729 Error Recovery for InternetTele-phony. Columbia University report, Spring 1997,
?http://www.cs.columbia.edu/-jdrosen/e688O/index.html
[6] NOLL P. MPEG digital audio coding. IEEE Signal Processing Magazine, September 1997:59-81.
[7] SALAMI R. ITU-T G.729 Annex A: Reduced complexity ?8kb/s CS-ACELP codec for digital simultaneous voice
?and Data. IEEE Communications Magazine,Sept.1997:56-63.
[8]?HWANG Shaw Hwa. Computional improvement for G.729?standard[J]. Electronic Letters. 22nd June 2000:1163-1164.
[9] ?MERMELSTEIN P, QIAN Ya sheng. Analysis by synthesis ?speech coding with generalized pitch prediction[D]. IEEE?International Conference on Acoustics, Speech and Signal?Processing, Vol. I of VI,1-4(HC), 1999.
[10] COMBESCURE P, SCHNITZLER J. A 16, 24, 32kbit/s?wideband speech codec based on ATCELP[C]. IEEE
?International Conference on Acoustics, Speech and Signal?Processing, Vol. I of VI,5-8(HC), 1999.
[11] MONTMINY C, ABOULNASR T. Improving the performance of ITU-T G.729A for VoIP[J].