
摘 要:提出了一種改進互信息的譯文選擇方法,認為詞語的譯文的選擇不是孤立進行的,上下文對譯文的選擇有著重要的意義,通過對已有的互信息公式加入翻譯模型特征進行改進,結合翻譯模型與互信息來選擇最佳譯文,經過BLEU(BiLingual Evaluation Understudy)作為機器評價準則的實驗結果表明,該方法優于傳統的互信息詞語譯文選擇的方法。
關鍵詞:互信息;譯文選擇;翻譯模型;譯文選擇模型
譯文選擇是指根據從語料庫中學習翻譯知識,為源語言詞選擇對應的目標語言詞。詞譯文選擇的好壞決定了機器翻譯系統的質量。Gale等人[1]應用基于大型英法對齊語料庫的統計方法,對6個常見的歧義詞的消歧正確率在82%~86%。劉小虎建立多上下文特征的詞義消歧統計模型,對歧義詞“interest”消歧測試的正確率達到80%[2];而通過在英漢機譯系統的譯文選擇中引入改進的ID3機器學習方法[3],歧義詞“interest”消歧測試的正確率可達到91%,荀恩東[4]在譯文選擇中使用以消歧矩陣為計算背景的貪心算法。Dagan[5]等人提出利用目標語同現統計消除源語言歧義的思想。哈爾濱工業大學BT863-2英漢機譯系統繼承Dagan的思想,譯文選擇的正確率為75%。術語相關性計算的研究比較典型,有EMMI weighting measure[6]、Term Similarity[7-9],本文方法與參考文獻[10]中提出的查詢翻譯中用到的方法有些相似。
1 譯文選擇模型
Ballesteros和Croft[8]認為對語料庫進行共現頻率的統計有助于消除翻譯的歧義問題。他們假定正確的翻譯更可能在同一個目標句子中共現,否則相反。參考文獻[7-9]也使用相類似的方法選擇最佳的詞語翻譯。
正是因為各個詞之間的關系不是相互獨立的,本文提出詞語相關性和翻譯概率相結合的方法來選擇相應的詞語翻譯,而不是逐詞孤立地翻譯。當翻譯一個詞語時,其他待翻譯詞的候選翻譯會成為它的上下文信息,這是本文進行翻譯選擇的原則。給定一個待翻譯的英文詞語的集合,通過貪心算法和下文中的公式(5)找到每個詞的正確譯文。
例如,輸入NP(Noun Phrase):IC card intelligent door lock。
在本文的雙語詞典中,“intelligent”對應的翻譯候選有:(1) 智能國;(2) 智力。依次類推本例中的目標集合T為{“IC”,“卡”,“門”,“通道”,“鎖”,“鎖頭”}。目標集合的獲得是通過在雙語詞典中查找每個源語言詞對應的漢語翻譯候選組成的集合。通過公式(1)~(3)[11]計算,找到最可能的目標翻譯,上例計算得到的翻譯結果為“IC 卡 智能 門 鎖”。
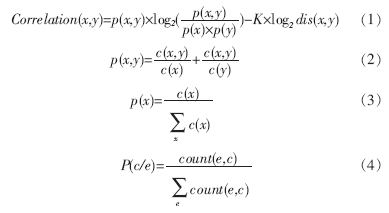

具體算法如圖1所示。

2 實驗結果及分析
本文將翻譯概率加入到公式(1)中,結合翻譯概率與互信息來進行譯文的選擇,對比實驗結果可知,翻譯概率對翻譯結果有較大的提高。
為了充分證明該結果,從英漢術語實例庫中,隨機挑選500個實例進行對比測試,采用NIST發布的最新版本mteval-v11b.pl作為自動翻譯結果的評測工具,實驗結果的曲線圖如圖2所示。

從表1中可以看出,加入翻譯概率后,從1-gram到4-gram的BLEU值都有所提高。為了更加清楚地顯示其對比效果,可以參見圖2。
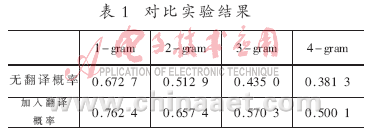
舉一具體實例來說明上面原因。例如:輸入NP:Safety non-tipping mosquito incense device,在不加入翻譯概率時,只通過公式(1)計算得出翻譯結果為:“安全不倒蚊蚊扣掣座”。
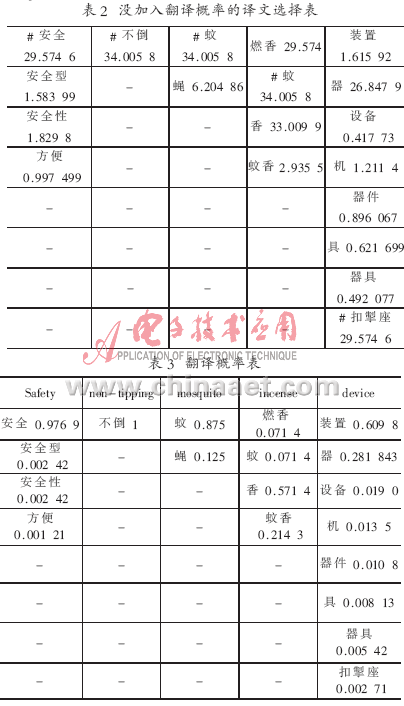
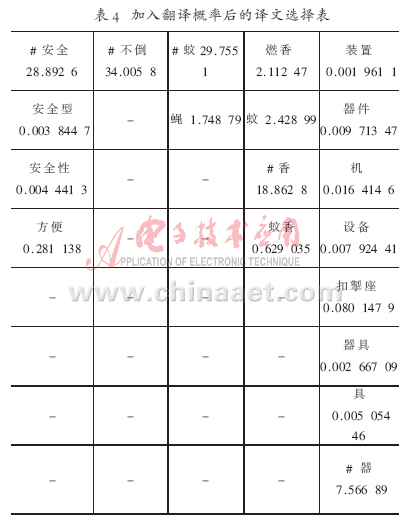
分析其原因,從表2可知,在沒有加入翻譯概率之前,通過公式(2)計算,“incense”選擇了“蚊”這個譯文,因為“蚊”的值最大,如表3所示。在加入翻譯概率改進之后,通過公式(5)計算,結果如表2所示,由于其翻譯概率很小,因此就會選擇到更合適的譯文“香”。(“#”表示選擇的譯文)根據表4,正確的譯文為:“安全 不倒 蚊 香 器”。
譯文選擇的好壞是機器翻譯質量提高的關鍵。本文提出的改進互信息的譯文選擇方法,其中對互信息的理論作了簡單介紹,對譯文選擇的相關研究也進行了簡單描述。通過對比實驗分析證明了該方法在已有的互信息方法上加入翻譯模型特征后,翻譯效果得到顯著地提高,BLEU值提高了0.1左右。
參考文獻
[1] WILLIAM G, KENNETH C, DAVID Y. Using bilingual materials to develop word sense disambiguation methods[C]. The 4th Int’l Conf on Theoretical and Methodological Issues in Machine Translation, Montreal, Canada, 1992.
[2] LIU Xiao Hu, Li Sheng , Zhao Tie Jun . Statistical model selection for word sense disambiguation(in Chinse)[J]. Communications of Chinese and Oriental Languages Information Processing Society, 1997, 7(2): 69-75.
[3] 劉小虎. 英漢機器翻譯中詞義消歧的研究[M]. 哈爾濱:哈爾濱工業大學, 1997.
[4] 荀恩東, 李生, 趙鐵軍. 基于漢語二元同現的統計詞義消歧方法研究[J].高技術通訊, 1998, 10(8): 21-25.
[5] DAGAN, LILLIAN L, FERNANDO P. Similarity-based models of cooccurrence probabilities[J]. Machine Learning, Special Issue on Natural Language Learning, 1999, 34(1-3): 43-69.
[6] RIJSBERGEN V . Information retrieval[J]. 2nd ed. Butterworths, London, 1979.
[7] ADRIANI M. Using statistical term similarity for sense disambiguation in cross-language information Retrieval[C]. Information Retrieval, 2000,2: 69-80.
[8] BALLESTEROS L, CROFT W B Resolving ambiguity for cross-language retrieval[C]. In Proceedings of the 21st International Conference on Research and Development in Information Retrieval,1998.
[9] BALLESTEROS L , CROFT W B. Phrasal translation and query expansion techniques for cross-language information retrieval[C]. In: Proceedings of the 20th International Conference on Research and Development in Information Retrieval, 1997: 84-91.
[10] GAO J F , NIE J Y. A study of statistical models for query translation:finding a good unit of translation[C]. In SIGIR, 2006.
[11] GAO Jian Feng, NIE Jian Yun, ZHANG Jian, et al. Improving query translation for cross-language information retrieval using statistical models[C]. In SIGIR’01, NewOrleans, Louisiana, 2001: 96-104.