
摘 要: 目前常用的個性化推薦系統模型通常是基于協同過濾或者是基于內容的,也有部分基于關聯規則的。這些算法沒有考慮事務間的順序,然而在很多應用中這樣的順序很重要。文章提出了一種簡易的基于序列模式的推薦模型,并且考慮到大規模數據的處理,結合了MapReduce編程模型。這種簡易的推薦模型可以用來輔助通常的個性化推薦系統。
關鍵詞: 推薦系統;序列規則;MapReduce
21世紀以來,隨著互聯網的飛速發展,人類已經進入信息社會的時代。互聯網對人們的生活影響越來越大,越來越多的人通過互聯網發布和查找信息,網絡成為了人們生活中必不可少的一部分,也成為信息制造、發布、處理和加工的主要平臺。現如今,互聯網已經逐漸參與到人們工作、生活、學習的各個方面,成為人們獲取所需信息、進行學習工作和信息交流的主要場所,并對人們的生活和社會的發展產生了巨大影響。
個性化推薦系統是一種以海量數據挖掘為基礎的智能平臺,這個平臺借助于電子商務網站來為顧客提供因人而異的個性化決策支持和信息服務。個性化推薦系統逐漸地被應用于各種商業網站,它因人而異地根據每個用戶的喜好主動地為其預測、推薦符合需求的商品,從這一點上彌補了信息系統的不足。隨著個性化推薦系統的不斷完善,各種算法被深入研究。目前最常用的推薦模型是以協同過濾為基礎的。盡管基于協同過濾算法的應用比較成熟,但它有著自身固有的缺點[1],這使得它需要與其他方法結合使用。
本文第1部分介紹了MapReduce編程模型,第2部分描述了一種簡易的基于序列模式的推薦系統的框架,第3部分介紹該框架在MapReduce模型下的實現,最后在總結部分提出了該框架的不足及需要改進的地方。
1 MapReduce編程模型
2004 年,谷歌發表論文向全世界介紹了GFS[2]和MapReduce[3]等模型,為大規模并行數據的計算和分析提供了重要的參考。MapReduce編程模型通過顯式的網絡拓撲結構盡力保留網絡帶寬,并盡量在計算節點上存儲數據,以實現數據的本地快速訪問,從而帶來了良好的整體性能。
MapReduce的設計靈感來自于Lisp等函數式編程語言中的map和reduce原語,相應的map和reduce函數由用戶負責編寫,它們通常遵循如下常規格式:
Map:(K1,V1)→list(K2,V2)
Reduce:(K2,list(V2))→list(K3,V3)
具體的MapReduce操作流程如圖1所示。
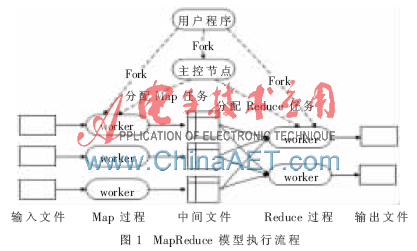
對圖1中的流程可以描述如下:
(1)用戶程序利用MapReduce相關接口先把輸入文件劃分為若干份,每一份的大小根據其分布式文件系統的塊的大小進行設定,然后使用fork在系統中創建主控進程(master)和工作進程(worker)。
(2)主控進程負責調度,為空閑worker分配作業(Map作業或者Reduce作業)。主控進程根據輸入文件的劃分分配相應的Map作業,同時,主控進程還將分配若干個Reduce作業。
(3)被分配了Map作業的worker,開始讀取對應分片的輸入數據,Map作業數量由輸入文件的劃分決定,與split一一對應;Map作業從輸入數據中抽取出鍵值對,每一個鍵值對都作為參數傳遞給map函數,map函數產生的中間鍵值對被緩存在內存中。
(4)緩存的中間鍵值對會定期寫入本地磁盤,而且被分為R個區,R的大小由用戶定義,將來每個區會對應一個Reduce作業;這些中間鍵值對的位置會通報給master,master負責將信息轉發給Reduce worker。
(5)主控節點通知分配了Reduce作業的worker它負責的分區在什么位置,當Reduce worker把所有負責的中間鍵值對都讀過來后,先對它們進行排序,使得相同鍵的鍵值對聚集在一起。因為不同的鍵可能會映射到同一個分區也就是同一個Reduce作業,所以排序是必須的。
(6)Reduce worker遍歷排序后的中間鍵值對,對于每個唯一的鍵,都將鍵與關聯的值傳遞給reduce函數,reduce函數產生的輸出會添加到這個分區的輸出文件中。
(7)當所有的Map和Reduce作業都完成了,master將會喚醒用戶程序,用戶程序對MapReduce平臺的調用由此返回。
MapReduce是一個簡便的編程模型,編程人員只需要實現其中的Map函數和Reduce函數即可。
2 框架描述
序列模式挖掘[4]是指找出所有滿足用戶指定的最小支持讀的序列,每個這樣的序列成為一個頻繁序列,或者一個序列模式。本文描述的算法基于序列模式挖掘,但是不考慮最小支持度,并且經過一次循環即可挖掘出模式,所以不存在產生候選項集。
通常個性化推薦系統分為3個階段:數據預處理階段、模式發現階段和推薦階段。其中數據預處理階段和模式發現階段都是推薦系統定期執行的(即離線部分),而推薦階段是實時的(即在線部分),因為系統需要通過用戶訪問的信息及時生成推薦信息。

在推薦階段,需要對用戶瀏覽過的頁面實時地進行分析,并預測用戶要點擊的頁面,動態地為用戶推薦可能要瀏覽的頁面,因此在本階段引入活動窗口。如果根據用戶最新瀏覽的兩個網頁進行推薦,則窗口大小為2。為便于理解,暫時討論活動窗口為3的情況。例如用戶u的活動窗口為〈A,B,C〉,假設用戶u下一個頁面點擊了頁面D,則活動窗口改為〈B,C,D〉,在此基礎上用戶u下一個頁面點擊了頁面D,則活動窗口改為〈B,D,C〉。如圖3所示。系統根據用戶的活動窗口,在已經挖掘到的模式中進行查詢,如果查詢到結果頁面,并且不止一個結果頁面,則可以根據模式比值進行相應處理,可以將比值最高的作為推薦頁面返回給用戶,也可以將比值排名前幾的作為推薦頁面返回給用戶。

3 MapReduce算法設計
在MapReduce算法設計[5]中,定義活動窗口的大小為2,并且默認數據經過預處理并保存在文本文件中,文本文件的一行為一個用戶的事務,一個單詞表示為一個項,項與項之間用空格隔開。
3.1 Map階段
Map階段輸入數據的鍵值對,Key為文本的行標,在本文中沒有實際意義,Value為文本中的一行數據。Map階段的偽代碼如下:
輸入:(key, value)
輸出:(word, one)
方法:map
{
line = value.toString();
pages = line.split(“ ”);
length = pages.length();
//通過三層循環發現模式
for(i=0; i<length-2; i++)
{
for(j=i+1; j<length-1; j++)
{
for(k=j+1; k<length; k++)
{
word=pages[i]+“ ”+pages[j];
one=pages[k];
//輸出結果
output.collect(word,one);
}
}
}
}
3.2 Reduce階段
在Reduce階段,Reduce工作節點從遠程Map工作節點讀取中間結果。在此階段中,統計出模式出現的頻率,并得出與事務總數的比值,最后輸出結果鍵值對。
輸入:(word, values)
輸出:(word, sum)
方法:reduce
{
//通過循環發現模式出現的頻率
while(values.hasNext())
{
value=values.next().get();
result=resultMap.get(value);
if(null != result)
{
result += 1;
resultMap.put(value,result);
}
else
{
resultMap.put(value, 1);
}
}
itr=map.keySet().iterator();
//根據頻率得出與事務總數的比值
while(itr.hasNext())
{
key=itr.next();
ratio=map.get(key)/sumt;
resultBuffer.append(key+“:”+ratio);
}
//輸出結果
output.collect(word, resultBuffer);
}
本文提出了一種簡易的基于序列模式的推薦模型,并結合MapReduce,實現了在大數據條件下進行模式挖掘的系統,彌補了常見的個性化推薦系統缺少時序的缺點,可以作為輔助的個性化推薦系統的應用。但本文缺少實驗數據,沒有進行實現分析,從而略顯遺憾。并且存在以下問題需要在以后的工作中繼續研究:
(1)個性化推薦的研究是基于用戶行為的研究,尤其是用戶Web瀏覽行為[6],用戶對不同類別的Web瀏覽習慣存在較大的差別。本文在用戶事務和活動窗口中均沒有考慮重復頁面的情況,并且活動窗口固定大小,因此在后續工作中應加入特定條件下用戶行為的研究。
(2)在事務中的項較多的情況下,可以考慮對項進行分類的策略,但是不同類別的項之間也可能存在關聯,在活動窗口中也可引入類別的概念,可以考慮同類別項之間的前后順序,而不像本文只單純地考慮瀏覽頁面的順序,這也將在后續工作中進行研究。
參考文獻
[1] SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based collaborative filtering recommendation algorithms[C].In Proceedings of the Tenth International. World Wide Web Conference on World Wide Web,2001.
[2] GHEMAWAT S,GOBIOFF H,LEUNG S-T.The Google file system[C].Procedings of 19th ACM Symposium on Operating System Principles,2003:29-43.
[3] DEAN J,GHEMAWAT S.MapReduce: simplified data processing on large clusters[J].Communications of the ADM 50th Anniversary lssue:1958-2008,2008,51(1):107-113.
[4] AGRAWAL R,SRIKANT R.Mining sequential patterns[C]. In Proc. of the Intl.conf.on Data Engineering,1995:3-15.
[5] WHITE T.Hadoop:the definitive guide[M].Yahoo Press,2010.
[6] MOBASHER B,DAI H,LUO T,et al.Effective personalization based on association rule discovery from web usage data[C].Proceedings of the 3rd International Workshop on Web Information and Data Management,2001:9-15.