
文獻標識碼: A
文章編號: 0258-7998(2013)10-0112-04
中高速無線傳感器網絡[1]用于包括環境檢測、視頻多媒體等多種混合類型業務,網絡負載通常很大,區域節點密度差異大,區域負載波動大。傳統無線傳感器網絡的MAC協議競爭窗口滑動緩慢,對于負載波動大的業務會造成過渡時間長以及資源浪費等,不能滿足數據復雜的中高速無線傳感器網絡[2]。目前出現了針對無線傳感器網絡MAC協議的多種有效的退避算法,典型退避算法有: (1)二進制指數退避算法BEB(Binary Exponential Backoff)[3] ,其特點是發生沖突時競爭窗口按二進制指數增長,發送成功時則降至最小值。其缺點是總是有利于最近發送成功的節點而公平性差, 且隨著節點數增加而碰撞概率急劇增大, 造成網絡性能迅速下降。(2)倍數增加線性遞減退避算法MILD(Multiplicative Increase Linear Decrease)[4],當網絡節點數較多時,MILD由于競爭窗口變化較平滑,其吞吐率性能略優于BEB。但當網絡有中等數目的節點時,則由于競爭窗口線性遞減而顯得縮小相對較慢,使節點競爭窗口值往往大于合理值。(3)CIMLD(Conic Increase Multiplicative Linear Decrease)算法[5]采用分段二次曲線計算倍乘退避因子來調節退避窗口,能夠在不同區域中以不同速率解決信道沖突,但流封鎖信道問題還沒有完全解決。(4)PTTL(Preferentially Transmitting and Different Traffic Levels)退避算法[6]根據網絡流量判定的級別來改變退避窗口大小,賦予轉發節點一定的信道接入優勢來提高前傳效率而減少時延,但對網絡流量變化適應性較弱。
這些退避算法各具優勢,但在負載波動變化急劇、數據復雜的中高速無線傳感器網絡環境中,網絡性能則大幅下降。因此,本文在深入研究PTTL退避算法的基礎上,提出一種密度預測與服務分級的MAC退避算法DPSC(Density Prediction and Service Classification),以達到提高網絡信道利用率與網絡吞吐量的目的。
1 PTTL退避算法介紹與分析
PTTL退避算法主要思想是:流量分級與轉發優先。即節點通過偵聽信道狀態來判斷當前網絡流量級別,并對轉發節點賦予較小競爭窗口而增大其信道接入概率。PTTL退避算法描述如下:
(1)空閑狀態,CW=max(CWmin,CW-i3),其中i是連續偵聽到空閑時隙數,CWmin是窗口最小值。
(2)發送成功,CW=max(CWmin,CW-s2),其中s是連續成功競爭信道并發送報文成功次數。
(3)發送失敗,競爭窗口CW為:
CW=min(CWmax,CW*(C+1)),C≤CmaxCW=CWinit, C>Cmax
其中C是連續競爭信道失敗次數,Cmax是最大退避次數,CWmax是窗口最大值。
(4)節點是轉發節點,則CW=CWmin。
總的來說,PTTL退避算法簡便易行,在網絡負載較重的網絡環境中性能良好。但PTTL退避算法并沒有服務分級,即不同業務類型數據以相同的機會接入信道,造成關鍵數據延遲,不能反映實際需求。且節點是轉發節點,則CW將無條件降低到CWmin,雖然這樣能夠在一定程度上提高轉發能力并保證數據轉發優先,但是當網絡負載嚴重時,不區分服務類型的無條件降至最小值CWmin,會造成碰撞概率急劇增加,反而與盡快將數據發送出去的初衷相反。因此關鍵類型數據應該具有接入信道優先權,提高優先級數據的傳輸率,減少關鍵類型數據時延來滿足應用實時性需求。
2 DPSC退避算法設計
為了提高網絡負載重且負載波動急劇的中高速無線傳感器網絡性能,基于PTTL退避算法提出密度預測與服務分級MAC退避算法DPSC。主要創新點如下:
(1)網絡節點數目進行加權遞推平滑預測。節點密度與鄰近節點數目是一一映射關系,即某節點的鄰近節點越多,此節點區域的節點密度越大。假設網絡自適應占空比p∈[0,1],即節點每周期處于活動狀態概率為p。在每個估算周期i∈[1,n],利用競爭窗口來實現計算鄰近節點,且計算節點數是指除開周期1~i-1中已計算的所有醒來鄰近節點。在估算周期i中,詢問節點發送詢問包REQ。接收到詢問包REQ且未有回答的醒來節點時,在M個時隙中隨機選擇一個時隙回復一個裝載唯一身份ID的回復包ANS。詢問節點在第i窗口成功收集分組Gi數目并記錄ID。由伯利努試驗二項分布可知占空比為p、實際鄰近節點數目為N且發生k次的概率為:

3.1節點密度預測分析
鄰近節點數目的最大似然估算值N*與節點占空比p有關,占空比p的大小決定N*的估算精確度。當前網絡鄰居節點數Nc與平滑因子l、權重系數Cj相關,此處取l=5,C1=0.2,C2=0.4,C3=0.6,C4=0.8,C=1.0。其中相對誤差e=|Nc-N|/N,Nc是當前鄰近節點數目加權遞推平滑預測值,N是當前鄰近節點數目真實值。
從圖2可知,鄰近節點數目越多,占空比p越大,則當前鄰近節點數目加權遞推平滑預測值與真實值相對誤差e越小,即平滑預測值越接近真實值,估算精確度越高。同理,對于節點密度大的區域節點可以設置較低的占空比p進行估算而得到可靠的鄰近節點數目估算值,且減少估算周期偵聽所消耗的能量。

3.2 系統時延分析
從圖3可知,節點數目較少時各算法端到端時延基本相同,但節點數目較多時的時延相差甚遠。DPSC算法時延增加速率最小,因為能夠根據鄰近節目數目動態地修改競爭窗口,減少碰撞概率與重發次數,從而減少端到端時延,能夠適應不同節點數目的網絡環境。
3.3 系統吞吐量分析
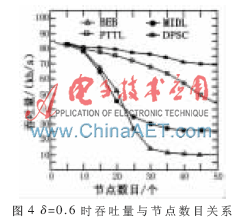
從圖4可知,隨著節點密度增大吞吐量都有所下降,在節點數目小于10時吞吐量大致相同,之后出現大幅度差距。因為隨著節點數目的增加,節點沖突概率將會增大,所以各種算法吞吐量都有所下降。其中DPSC算法下降速度最慢是由于鄰近節點數目能自適應競爭窗口,從而有效地提高信道利用率,相對PTTL算法平均提高15%。其余三種算法都不太適應于高節點密度的網絡環境,特別是BEB算法吞吐量下降最快。
3.4系統能耗分析
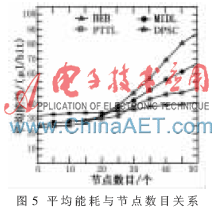
從圖5可知,各退避算法成功發送每比特數據的平均能耗隨著系統網絡節點數目的增加而增加。在鄰近節點少的網絡系統中,其他三種算法能耗低于DPSC算法,因為密度低而競爭信道的沖突少,數據發送成功率高,而DPSC算法卻因節點估算預測的周期偵聽耗能略高。但高密度時DPSC算法因為根據節點數目動態地改變競爭窗口而降低沖突概率,減少重傳次數,所以平均能耗明顯低于其他三種算法,相對于PTTL算法平均下降5%。
本文退避算法DPSC通過二項分布概率模式對鄰近節點數目進行最大似然估算并進行加權遞推平滑預測,精準地估算出鄰近節點數目,實現競爭窗口自適應節點密度的目的;根據服務分級思想,引入服務分級因子δ實現服務級別高的數據能優先發送;引入負載分級因子κ表示負載級別并賦予數據積壓的節點優先發送權;引入多跳傳發優先因子μ實現數據前傳的連續性與減少時延,滿足關鍵數據多跳傳輸實時性要求。DPSC退避算法與其他三種算法在節點低密度與低負載情況下網絡性能差別不大,但在節點高密度與高負載情況下則表現出優越的網絡性能。進一步的工作將采用無線傳感器硬件平臺CC2430對DPSC退避算法進行實際性能測試。
參考文獻
[1] 王越超,程良倫.中高速傳感器網絡中基于服務區分的QoS路由算法研究[J].計算機應用與軟件,2010(8):152-158.
[2] CHIA W C, CHEW L W, ANG L M, et al. Low memory image stitching and compression for WMSN using stripbased processing[J]. International journal of sensor network, 2012,11(1):22-32.
[3] PANTAZI A,ANTONAKOPOULOS T. Equilibrium point analysis of the binary exponential backoff algorithm[J].Computer Communications, 2001,24(18):1759-1768.
[4] Zhang Yi, PIUNOVSKIY A, AYESTA U,et al. Convergence of trajectories and optimal buffer sizing for MIMD congestion control[J]. Computer Communications, 2010,33(2):149-159.
[5] 奎曉燕,杜華坤. CIMLD:多跳Ad Hoc網絡中一種自適應的MAC退避算法[J]. 小型微型計算機系統, 2009,30(4):679-682.
[6] 余慶春,譚獅. 一種基于轉發優先及流量分級的無線傳感器網絡退避算法[J]. 計算機應用研究,2012,29(5):1846-1849.
[7] CAMILLO A,NATI M, PETRIOLI C,et al. IRIS:Integrated data gathering and interest dissemination system for wireless sensor networks [J]. Ad Hoc Networks, 2011, 11(2):654-671.