
摘 要: 本文測試了基于網格計算技術的PC 集群系統在大規模油藏模擬中的使用,測試結果顯示大規模油藏模擬在最新的PC集群系統上高效運行是可行的。
關鍵詞: 油藏模擬 網格計算 PC集群 高速網絡
1 數字油藏模擬對計算機性能的要求
在油田開發、地質研究、大規模并行油藏模擬應用方面,目前使用的主流數值模擬軟件有美國Schlumberger公司的并行Eclipse,美國Landmark公司的并行VIP和加拿大CMG公司的STARTS。這3個軟件都能夠提供數值模擬的前期預處理、模擬、后期處理的完整工作流模式,模擬黑油、組份和裂縫模型。當前被模擬的油藏模型從幾十萬個單元到幾千萬個單元,運行平臺主要是在專業的并行機。在未來幾年,隨著老油區開發難度的增大,油藏模型的面積和數量將會明顯地增加和擴大。如果繼續用傳統的并行計算機來模擬,為了達到理想的模擬速度和效果,其硬件平臺的投資將很高。由于網格計算技術的發展,并行機市場不斷萎縮,其系統的擴容、維護等都存在很大的問題。為了應對面臨的挑戰,本文對今后的數值模擬的硬件平臺作了一系列性能評估測試,其目的就是要去驗證和評估一個低成本、高性能的計算平臺,以滿足企業對油藏模擬的不斷增長的計算需求。
2 網格計算的發展
隨著微處理器、高速網絡、網格計算技術和Linux系統的發展,基于低成本的PC架構的服務器和高速網絡構成的Linux集群系統在高性能并行計算領域逐漸興起。網格計算為工程師、科研人員、和其他需要專門、高性能計算的人員提供了無縫的、對分布式計算的透明訪問的服務,促成對已安裝的IT設施的更好使用率,跨平臺和地區的計算能力的更靈活管理和對資源的更好訪問。
網格計算的目標是實現資源的集中調度、模塊化可擴充的計算節點、資源的透明訪問和負載均衡。當前正在建設的網格系統都是以PC集群作為網格主節點,再通過網格中間件,將其他異構的系統加入其中。PC集群是通過高速交換網絡連接的PC服務器的集合,其優秀的性能得益于其計算核心(CPU)的性能的極大提高。目前,典型的PC集群采用的處理器的性能(例如主頻為1.8GHz的Opteron處理器)要遠遠超過傳統的并行機采用的處理器,3個處理器的性能(SPECfp2000,主要用于衡量處理器浮點運算性能)對比如圖1所示。

Power3處理器用于IBM SP2并行系統,Xeon以及Opteron處理器被廣泛地使用在低價位的PC服務器上。SPECfp2000測試值僅僅是衡量系統性能的一個指標,一個系統的整體性能高低還是要以應用軟件的運行效率來判斷。處理器性能測試指標和處理器價格相比,PC集群比并行計算機有更好的性價比。
當前IBM SP2并行機是新疆油田作數值模擬的計算平臺,運行LandMark VIP和Schlumberger Eclipse。在國外,石油公司逐步采用了基于網格技術的PC 集群系統替代原有的并行機來作油藏模擬。
3 測試平臺的選型
為了驗證集群系統是否可行,我們和應用集成商合作搭建了32個節點的基于雙AMD Opteron 64位處理器的系統,節點間通信實驗了Infiniband、Myrinet、千兆以太網3種互聯方式。系統支持MPI調用和OpenMP二種并行機制。油藏模擬軟件選擇Landmark公司的VIP,計算網格的資源調度、作業分配都由VIP軟件來完成。
測試在IBM SP2并行機和運行Linux系統的PC集群平臺上進行。IBM SP2使用4個節點,8個222MHz Power3處理器。PC集群系統是基于千兆以太網、Myrinet 高速交換技術和AMD Opteron 64位處理器。在配置集群系統時,應從以下5點考慮:處理器(CPU)、網絡連接、內存、I/O以及管理軟件等工具。
在集群的處理器方面,主要考察了Intel的Xeon處理器以及AMD的Opteron處理器。因為Intel處理器應用范圍廣,應用軟件兼容性好,而AMD Opteron 64位處理器可以向下兼容32位應用,可以保護以前在32位平臺上的軟件投資,并且在未來軟件升級到64位后,無需更換硬件平臺,保護了硬件的投資。從處理器性能等方面綜合考慮,選擇了基于Opteron處理器的集群平臺。
在高速交換方面有幾種選擇:千兆以太網、Myrinet、Quadrics、Infiniband。4種交換網絡的性能參數對比如表1所示。
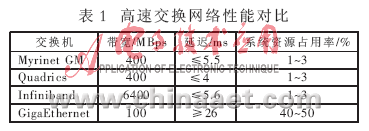
VIP并行油藏模擬軟件要求高速、低延遲的通信方式,因為計算節點之間需要大量的數據交換去計算相鄰網格單元邊緣處的偏移。千兆以太網價格低,但是帶寬窄、延遲大,可以作為集群管理和I/O網絡,但不適于節點間的數據通信(節點間的通信帶寬至少要200MBps)。Myrinet、Qua-
drics、Inifiband在帶寬和延遲方面都可以滿足VIP軟件的要求,結合應用需求最終選擇Myrinet。
存儲選擇采用SCSI技術的NAS系統,計算節點訪問存儲采用千兆以太網。集群系統的管理采用了基于瀏覽器的監控軟件,可以實時檢測每個計算節點的CPU、機箱內溫度、風扇轉速等參數以及系統資源利用率等。
4 測試結果
在測試中,選擇了國外某油田100萬個網格(有效網格85萬個)、8個斷層、7個組分、100個井的模型。從2001年開始模擬時間20年,并行分區64個,共設計了單個節點(2個CPU)、4個節點(8個CPU)、8個節點(16個CPU)、16個節點(32個CPU)、32個節點(64個CPU)5個方案進行測試。交換網絡采用千兆以太網和Myrinet。在測試中,驗證了多處理器集群性能的關鍵指標:精度、解法穩定性、并行效率。
4.1 計算精度和解法的穩定性
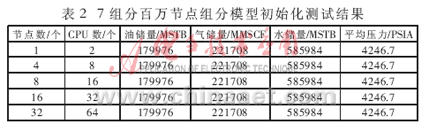
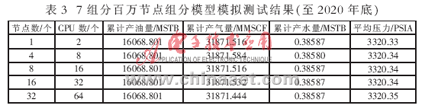
測試表明,幾個方案初始化結果的油儲量、氣儲量、水儲量、原始油藏壓力完全相同;計算到2020年底,幾個方案模擬結果的累計產油量完全相同,累計產氣量、累計產水量及平均壓力基本相同,如表2、表3所示。
4.2 并行效率
評價并行軟件效率高低的主要指標是加速比、加速效率、增量加速比和增量加速效率,其中加速比包括實際加速比和理想加速比2個概念。當運行某一作業時,實際加速比是指使用多個CPU時的作業運行時間與只用1個CPU時的作業運行時間之比;理想加速比是指使用多個CPU的理想運行時間與只用1個CPU的運行時間之比。加速效率指實際加速比與理想加速比之比的百分數。
4.2.1 千兆以太網(GbE)
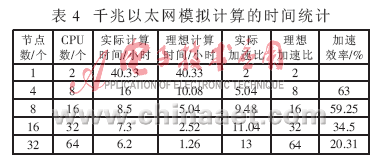
千兆以太網模擬計算的時間統計如表4所示。由表4可知,在千兆以太網環境下,4、8、16、32個節點的加速效率為63%~20.31%,其中4、8節點分別為63%、59.25%,16和32個節點的加速效率明顯下降,只有34.5%和20.31%,增量加速效率均不高,為59%左右。分析表明,隨著節點數的增多,節點與節點之間的數據交換占用了大量的時間,CPU的利用效率明顯降低。因此在多節點的情況下,節點之間的數據交換成為制約運算速度的瓶頸。
4.2.2 Myrinet交換網絡
由表5可以看出,8個CPU的加速比為6.92,加速效率為86%,16個CPU的加速比為12.22,加速效率為76%,均達到較為理想的加速比。
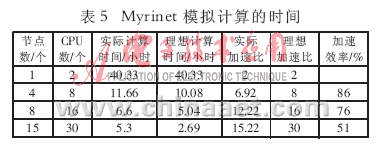
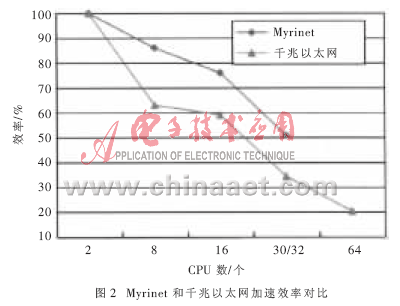
Myrinet和千兆以太網加速效率對比如圖2所示。圖2數據表明,這種緊耦合應用的集群系統中,由于并行節點間需要大的數據交換,所以節點間數據交換的效率將極大地影響并行軟件運算的效率,因此Myrinet以其高帶寬和低延遲而取得了比千兆以太網好得多的加速比。另外,將這組數據輸入到IBM SP2的4個節點8 CPU的并行機上模擬,系統運行了30.2個小時后,同樣CPU個數的基于Myrinet的PC集群的運算時間為11.66小時;基于千兆以太網的PC Cluster運算時間是16小時,速度比IBM SP2提高了2.6~1.9倍。而同樣配置的硬件平臺的價格相差就更大了。
4.3 其他相關問題
在測試中,其他例如兼容性、管理、I/O存儲等方面問題,需要在將來改進。
(1)Linux的兼容性問題。開源的Linux可以降低擁有成本,但由于硬件平臺的品牌太多,在支持不同的板卡、網絡等方面,缺乏統一的解決方案,因而在構建應用系統時,需要做很多的測試來保證軟件和硬件的匹配和兼容。
(2)現在的PC集群系統是由許多1U高度的機架式低端服務器集成在一個機柜內的,因此散熱等問題將考驗這樣一個集合的系統的穩定性。同時要考慮這么多通過網絡連接起來的、物理上獨立、邏輯上相關的服務器怎樣集中監控管理,才能保證其作為一個完整的系統發揮最佳的運算效能。所以選擇產品時,就要考慮設備廠商是否有對集群系統可靠的產品和完整網格計算的解決方案。目前國際上有許多網格的工程在開展,如Globus、Gridbus Tools等,而且涉及到網格中間件、資源調度、開發工具、安全等方面。因此在組建網格系統時要跟蹤這些工程的進展,才能有效地利用這些技術,最大地發揮網格系統的運算能力,達到最佳的性能指標。
(3)I/O存儲問題。在PC 集群系統中,由于計算節點間要共享存儲系統,當計算節點很多時,就存在著訪問網絡的瓶頸問題。目前有多種解決瓶頸問題的方案可供選擇,例如:①采用SAN方式解決計算節點的訪問瓶頸問題,但這種方案投資高。②后端采用SAN存儲網絡,前端采用多個I/O節點進行復雜均衡。③正在進行試驗的許多新方案,例如并行虛擬文件系統(PVFS)、面向對象的存儲(OOS)等。至于如何選擇,要從應用的性能、兼容性和成本費用等方面綜合考慮。
5 結 論
根據本文的測試,可得出以下一些結論:
(1)PC集群系統在油藏數值模擬是一個表現很不錯的硬件平臺,從性能和成本等方面都是很有競爭力的選擇。
(2)大規模的上百萬網格的油藏模擬在PC Cluster上運算是切實可行。
(3)系統管理、I/O問題將在大規模計算節點的集群中顯得更加突出。
(4)基于Linux的網格集群技術將在油田勘探開發中扮演更加重要的角色,所以在新的系統選型中應綜合考慮系統的性價比。
參考文獻
1 Buyya R.High Performance Cluster Computing Architectures and Systems.ISBN,1999;(1)
2 孟杰.MPI 網絡并行計算系統通信性能及并行計算性能的研究.小型微型計算機系統,1997;18(1)
3 Feng P,Jianwen C.Parallel Reservoir Integrated Simulation Platform For One Million Grid Blocks Case.超級計算通訊,2004;2(3)
4 Wheeler M F.Arbogast T,Bryant S et al.A Parallel Multiblock/Multidomain Approach for Reservoir Simulation. Paper SPE 51884 Presented at the 1999 SPE Symposium on Reservoir Simulation,Houston.Texas,1999