
文獻標識碼: A
文章編號: 0258-7998(2012)02-0127-04
在集群計算系統中,隨著系統規模的增大,通信效率是影響整個系統獲得高性能的關鍵因素之一。而隨著局域網傳輸性能的快速提高,Myrinet、Gigabit Ethernet和Infiniband等千兆位網絡設備已被廣泛使用,當前影響集群節點間通信性能的瓶頸已經從通信硬件的傳送開銷轉移到了通信處理軟件的開銷上,所以采用優化的通信協議是降低通信成本、提高結點間通信的有效手段。
在當前的集群通信應用中,普遍采用兩類通信結構,即核心級通信和用戶級通信。但由于它們設計的初衷并非是針對集群通信,所以并不適合當前集群環境的特點。為此,本文通過分析這兩類通信結構的特點,提出了以核心級通信為基礎,旁路內核中IP層及以上協議層,實現數據鏈路層直接與MPI通道接口層通信的新機制,并通過實驗驗證,為傳統集群的升級改造提供一種新的無連接、無差錯控制,開銷小、延時低的通信機制。
1 基于數據鏈路層的集群通信結構的提出
目前各種通信協議普遍采用兩種通信結構,即核心級通信和用戶級通信[1]。
1.1 核心級通信
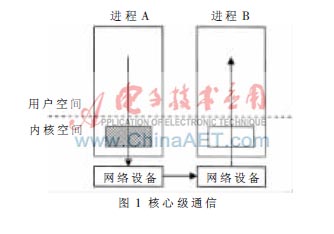
在核心級通信中,操作系統內核控制著所有消息傳遞中的發送與接收處理,并且負責它們的緩沖管理和通信協議的實現,設備驅動程序也是通過內核來完成所有的硬件支持與協議軟件處理的任務,如圖1所示。在通信過程中,系統要經過多次內核態與用戶態之間的數據拷貝才能夠實現數據的傳送。有數據表明[2],一般奔騰處理器的內存拷貝速率平均為70 Mb/s,但是由于操作系統在交換頁面時的 I/O 數據傳送都是阻塞操作,若出現缺頁中斷,其時延將會更大,所以頻繁的內存拷貝操作的開銷將是影響整體性能的瓶頸所在。因此,對于通信效率要求較高的集群計算系統,核心級通信是不適合的。
1.2 用戶級通信
在用戶級通信中,操作系統內核將網絡接口控制器NIC(Network Interface Controller)的寄存器和存儲器映射到用戶地址空間,允許用戶進程旁路操作系統內核從直接訪問NIC,直接將數據從用戶空間發送到網絡中進行傳輸。通信事件處理的觸發采用查詢方式而不是中斷方式,由于旁路操作系統內核,使得整個通信過程省掉了執行系統調用、用戶態與核心態之間的數據拷貝及用戶與內核的上下文切換等軟件上的開銷,進而減少對主機CPU資源的占用,縮短通信操作的關鍵路徑,實現通信與計算的重疊。如圖2所示[3]。
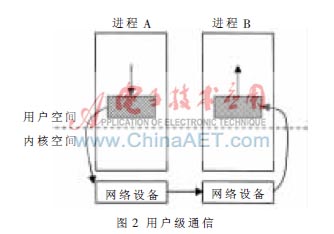
但是,采用用戶級通信協議時,通信過程中的所有操作均在用戶空間中進行,當用戶程序出錯或有惡意用戶進行破壞時,系統就很容易被破壞。這是因為系統數據結構中不僅包含本進程(或并行任務)及其相關信息,同時也包含與本進程無關的其他進程(或并行任務)的相關信息。若某一用戶(并行任務)出錯或失誤,都將會影響到其他用戶(并行任務)的執行,因而很難保證系統的安全性和可靠性,也無法保證并行任務間的相互獨立性。
1.3 基于數據鏈路層通信
為了既能保證系統安全、可靠以及并行任務間相互獨立,同時又能降低通信成本,本文提出了一種以核心級通信為基礎的基于數據鏈路層的通信結構,即在操作系統內核(以Linux內核為例)中旁路IP層、INET Socke層和BSD Socket層,使得數據鏈路層直接與應用程序的通道接口層通信。如圖3所示。
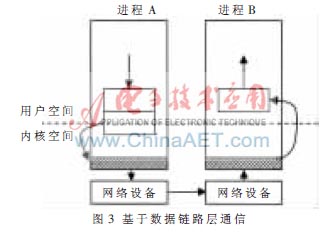
圖3中陰影部分表示通信關鍵路徑上數據鏈路層。在該通信結構下,系統在通信的關鍵路徑上將通過內存映射和內存拷貝兩種技術實現通信。在發送消息時,系統通過內存映射技術將消息映射到內核中的緩沖區,注冊協議標識,并調用數據鏈路層函數對其進行封包發送;在接收消息時,系統通過數據鏈路層的MAC地址進行尋址、接收消息,并通過內存拷貝直接將消息傳送到用戶空間中的應用程序,實現點到點通信。
與用戶級通信結構相比,基于數據鏈路層的通信結構在通信關鍵路徑上只增加了一次內存拷貝的開銷。同時,由于保留了數據鏈路層的通信,進而為系統的安全性、可靠性和并行任務間的獨立性提供了保障。此外,該通信結構可以屏蔽系統的硬件信息,使得在應用程序中不再出現與系統通信硬件有關的操作。
與核心級通信結構相比,該通信結構在通信關鍵路徑上減少了協議處理開銷、數據拷貝次數和冗余的差錯校驗,進而提高了系統的通信效率。
2 MPI的通信
MPI(Message Passing Interface)是為基于消息傳遞的并行程序設計提供一個高效、可擴展、統一的編程環境,是目前主流的并行編程模式,也是分布式并行系統的主要編程環境。在集群環境中MPI并行程序設計中使用的通信模式有阻塞通信、非阻塞通信和組通信,其中阻塞通信和非阻塞通信屬于點對點通信,而點對點通信也正是MPI其他通信的基礎。
在阻塞通信中,當發送調用函數MPI_Send后即被阻塞,這時,系統會將發送緩沖區中的數據拷貝到系統緩沖區,由系統負責發送消息,而發送者的操作只在拷貝操作完成時結束并返回,不必等待發送完成。但是,如果系統緩沖區不足或消息過長,導致拷貝失敗,則發送者將被阻塞,直到消息發送完成為止;同樣,當接收者在調用函數MPI_Recv后會被阻塞,直至收到匹配的消息為止[3]。
非阻塞通信主要是通過實現計算與通信的重疊,進而提高整個程序的執行效率。對于非阻塞通信,不必等到通信操作完全結束后才可返回,而是由特定的通信硬件完成通信操作。在通信硬件執行通信操作的同時,處理機可以同時進行計算操作,這樣便實現了通信與計算的重疊。發送者調用函數MPI_Isend或接收者調用數MPI_Irecv后,處理機便可執行其他計算任務。在發送(接收)操作開始時,發送者(接收者)使用請求句柄(request handler),MPI通過檢查請求來決定發送(接收)操作是否完成,發送者(接收者)通過調用MPI_Test來確定發送(接收)操作是否完成。在發送或接收操作期間,發送者不能更改發送緩沖區中的內容,接收者也不能使用接收緩沖區中的內容。若發送者(接收者)調用函數MPI_Wait,則發送者(接收者)會被阻塞,直到發送(接收)操作完成才能返回[4]。
由此可知,MPI點到點通信在發送緩沖區、接收緩沖區和內核中的系統緩沖區之間進行傳遞,并由內核發送或接收系統緩沖區中的消息,本文提出的新通信機制就是圍繞著系統緩沖區展開的。
3 基于數據鏈路層的MPI通信機制的設計與實現
若要實現本文所提出的基于數據鏈路層的集群通信機制,則需要開發一個中間件DLMC(Data_link Layer MPI Communication)用于提供雙方進行通信的底層交換協議、數據包校驗、用戶空間與內核空間的數據交換和重傳機制等。這里需要注意的問題有:
(1)編譯方式
對于Linux內核編譯分為直接編譯進內核和通過模塊編譯加載進內核。本系統采用模塊加載的方式進行編譯,其理由是由于系統是在傳統Linux網絡下進行的修改,只有MPI計算才會用到此中間件,而對于計算之外的部分仍然要依靠傳統的TCP/IP。例如計算前期的準備工作,雖然模塊加載比直接編譯的效率低,但它可以隨意動態加載和卸載,這樣不僅靈活,而且有利于開發、調試等工作。
(2)用戶空間和內核空間之間的數據交換
基于數據鏈路層的通信進程是在內核空間運行的,而MPI進程是在用戶空間進行的,所以需要在用戶空間和內核空間進行通信。通過利用Linux內核機制,在用戶空間緩存頁面以及物理頁面之間建立映射關系,將物理內存映射到進程的地址空間,從而達到直接內存訪問的目的。
在Linux中,對于高端物理內存(896 MB之后),并沒有與內核地址空間建立對應的關系(即虛擬地址=物理地址+PAGE_OFFSET),所以不能使用諸如get_free_pages()函數進行內存分配,而必須使用alloc_pages()來得到struct *page結構,然后將其映射到內核地址空間,但此時映射后的地址并非和物理地址相差PAGE_OFFSET[5]。為實現內存映射技術,其具體使用方法是:使用alloc_pages()在高端存儲器區得到struct *page結構,然后調用kmap(struct *page)在內核地址空間PAGE_OFFSET+896M之后的地址空間中建立永久映射。DLMC首先讓內核得到用戶空間中發送緩沖區的頁信息,再將其映射到內核地址空間,并且返回內核虛擬地址,以供DLMC直接將發送緩沖區中的數據傳遞到數據鏈路層進行發送,這樣就完成了用戶地址空間到內核地址空間的映射。
(3)校驗與重傳機制
由于數據鏈路層的傳輸是一種不可靠的網絡傳輸方式,涉及到對傳輸數據進行數據校驗重傳等工作。考慮到局域網或者機對機傳輸的穩定性和可靠性,系統校驗方式使用簡單的數據校驗和,重傳機制使用選擇重傳ARQ方案。當出現差錯必須重傳時,不必重復傳送已經正確到達接收端的數據幀,而只重傳出錯的數據幀或計時器超時的數據幀,以避免網絡資源的浪費。
(4)中斷機制
由于本系統改變了TCP/IP的傳輸機制,所以需要對發出的數據包進行協議標識。系統在初始化階段,調用內核的dev_add_pack()函數向內核注冊了標識為Ox080A的網絡數據處理函數。在發送數據包時,系統先通過kmap()函數將MPI的發送緩沖區sendbuff映射到內核映射緩沖區sysbuff,以軟中斷的方式通知系統,申請分配一個新的SKB來存儲sysbuff里的數據包,調用dev_queue_xmit函數,使數據包向下層傳遞,并清空sysbuff,釋放SKB。在接收端需要向內核注冊相應的硬件中斷處理函數,在接收到數據后喚醒上層的處理函數,并在netif_receive_skb函數(net/core/dev.c)中屏蔽將SKB包向上層傳遞的語句,改為將SKB里的數據以MPI數據包格式通過copy_to_user函數拷貝到MPI的接收緩沖區recvbuff中,完成數據的接收,其傳輸過程如圖4所示。

4 實驗結果與分析
4.1 實驗結果和方法
本實驗環境是一個4節點的Beowulf集群系統,每個節點包含一個PIV處理器和2 GB內存,操作系統采用Redhat Linux Enterprise 5,并行集群軟件為OPEN MPI 1.3。由于條件所限,加之實驗規模較小,本實驗采用MPI自帶的函數MPI_Wtime()來采集MPI計算的開始時間和結束時間,取二者的時間差作為程序的運行時間并對其進行比較和分析。
由于本實驗的目的是要測試基于數據鏈路層的通信機制的可行性,而該通信機制是在TCP/IP協議基礎之上構建的,所以本實驗對象將以單機系統、基于TCP/IP的MPI集群和基于DLMC的MPI集群作為參照平臺進行測試。在實驗用例設計上,考慮到兩種MPI集群的通信機制中的傳輸路徑不同,所以采用如下兩種測試方案:
(1)計算圓周率,主要測試系統的數學函數浮點計算性能,以點對點短消息傳輸為主;
(2)計算求解三對角方程組,主要測試通信和計算的平衡,以點對點長消息傳輸為主。
4.2 性能分析
(1)計算圓周率,如表1所示。
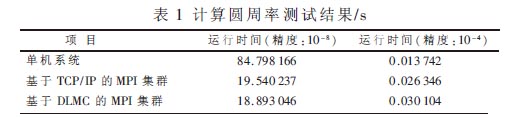
測試結果表明,在精度值設為10-8,精確值比較大時,基于TCP/IP的集群(4個進程)的運行時間是19.540 237 s,單機系統(單進程)運行時間是84.798 166 s,并行運算效果明顯。在精度值設為10-4,精確值比較小時,基于TCP/IP的集群(4個進程)的運行時間是0.026 346 s,單機系統(單進程)運行時間是0.013 742 s,這是由于并行運算過程中,參與運算的機器需要通過網絡傳遞消息,若計算量規模不大,則在網絡傳輸上花費的時間會比較多,所以反不如單機的運行速度快。從基于DLMC的集群與基于TCP/IP的集群運行結果對比看,在精度值較大時,前者略微快于后者,而在精度值較小時,后者略快于前者,這主要是因為基于TCP/IP的MPI集群在發送和接收的整個過程中,需要2次數據拷貝,即發送緩沖區到內核的拷貝和內核到接收緩沖區的拷貝,同時還有經過各協議層的開銷。而基于DLMC的MPI集群在整個的傳輸過程中,通過使用內存映射,只需要1次數據拷貝,同時旁路IP層及以上各協議層,在這種以短消息傳輸為主的測試中使得DLMC集群不能發揮其在網絡傳輸上的優勢,所以在精度值較大時,二者相差無幾;在精度值較小時,反而基于TCP/IP的集群更快一些,這是因為內存映射和內核操作所引入的開銷大于1次內存拷貝開銷而造成性能的下降。
(2)計算求解三對角方程組,如表2所示。

由測試結果表明,在傳輸消息較小時,基于DLMC的MPI集群花費的時間略微小于基于TCP/IP的MPI集群,這說明此時基于內存映射和內核調用等操作的開銷要高于兩次數據拷貝的開銷,造成網絡延遲略高。但隨著傳輸消息規模的增大,特別是消息大小超過1 MB時,基于內存映射和數據鏈路層協議的DLMC相對于具有2次內存拷貝的多協議機制的網絡延時要小得多,這樣使得系統的整體運行時間明顯低于傳統的TCP/IP集群。
由上分析可知,基于Linux數據鏈路層的集群通信機制是可行的。在該機制下構建的MPI集群系統完成了無IP條件下的數據傳輸,并且支持多用戶調用,在傳輸過程中減少了協議開銷、和內存拷貝次數,相比于TCP/IP傳輸有一定提高。但是基于數據鏈路層協議的特點,該機制只能在局域網范圍內運行,所以集群節點數量或規模會受到一定的限制,只能適合中小集群系統的應用。由于實驗條件的有限,對集群通信系統未能充分驗證,希望在今后的研發工作中能夠進一步加強。
參考文獻
[1] 馬捷.基于SMP結點的機群通信系統關鍵技術的研究[D]. 北京:中國科學院研究生院(計算技術研
究所), 2001.
[2] 可向民,李正虎,夏建東. 零拷貝技術及其實現的研究[J].計算機工程與科學,2000,22(5):17-24.
[3] 劉路,謝旻,張磊,等.用戶級通信中基于網絡接口的虛實地址變換技術[J]. 計算機工程與科學, 2008,(09):
154-157.
[4] WILLIAM G, LUCK E, SKJELLUM A. Using MPI:portable parallel programming with the message passing interface[M].2nd Edition. Cambridge, MIT Press, 1999.
[5] BUNTINAS D, GOGLIN B, GOODELL D,et al. Cache-efficient, intranode, large-message MPI communication with MPICH2-Nemesis[C].38th International Conference on Parallel Processing(ICPP-2009). 2009:462-469.
[6] 毛德操,胡希明.Linux內核源代碼情景分析[M].杭州:浙江大學出版社,2001.