
1 引言
隨著CPU設計位數與性能的不斷提高,對CPU執行單元中專用硬件移位寄存器的要求也越來越高。CPU移位寄存器的性能直接影響到所設計CPU對移位類指令的處理能力和執行速度。傳統結構的CPU中,移位寄存器的設計一般采用矩陣結構和樹狀結構。當CPU的位數達到32位,速度達到100M以上時,要在一個指令周期內對32位的數據進行32 位內任意移位,以前的設計方法已經很難達到要求。曾經有過對32位桶形移位寄存器的行為級描述,但其只適用于RISC指令集,并且作為CPU中的專用硬件為了達到功耗、速度和面積上的最佳,通常硬件電路采用全定制設計。
本文給出了一種可用于32位以上CPU執行單元的移位寄存器電路,并針對CISC指令集INTEL X86進行了優化(由于RISC指令集中移位類指令實現比較簡單,故沒有在文中討論);采用指令預處理的技術和通過冗余位,能很方便的實現帶進位標志CF移位和設置CF位,并使得每條移位指令的平均執行速度為兩個指令周期。它有效地提高了CPU對移位類指令的執行性能,并且作為一個基本的內核單元能很方便地移植到不同指令集(RISC或CISC)的CPU設計之中。
2 32位CPU中執行單元總體結構
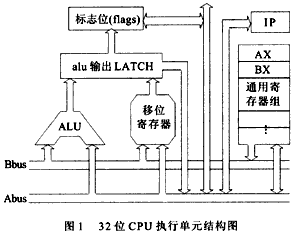
我們所設計的32位CPU的執行部分采用雙總線結構,數據總線(Abus,Bbus)的寬度是32位。由于移位類指令如果用ALU進行實現的話,必然會耗費太多的CPU周期,為實現在一個指令周期內對32位數據進行任意位的移位操作,因此有必要在執行單元中設計專用硬件移位寄存器,在執行移位類指令時由它進行32位數據的移位。
圖1給出了32位CPU執行單元總體結構數據流結構簡圖,并省略了所有控制信號。圖中Abus為雙向32數據總線,Bbus為單向32位數據總線。由于考慮到要實現INTEL X86系列所有的移位類指令(RCR,RCL,ROR,ROL等),所以移位寄存器在設計時采用雙輸入端,即實際該移位寄存器最大能實現64位移位。通過特殊的指令預設置方法,并通過增加冗余位實現標志位的設置。
3 移位寄存器單元的設計
3.1 矩陣移位器和樹狀移位器
在CPU中移位寄存器單元的設計一般采用的是矩陣結構和樹狀結構的移位器。
3.1.1 矩陣結構(Matrix Style)移位器
它的結構為一傳輸門組成的陣列。行數等于操作數據寬度,列數等于最多能移位數如圖2所示(以4位舉例)。
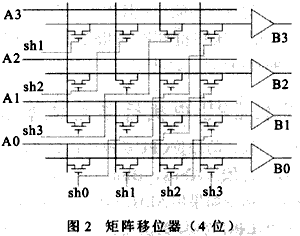
其中A3~A0是4位數據輸入線,sh3~sh0是4根控制信號線。每次進行N位移位操作,對應的shN為高,其它控制信號為低。
這種結構的優點是:(1)數據傳輸的速度快,每個信號到達輸出端只經過了一級傳輸,不受移位器位數限制;(2)版圖很規整。缺點是:(1)每根控制信號的負載太大,如32位移位器,每根信號線(sh0,sh1,……sh31)都要驅動32個開關管;(2)所需晶體管數目太多,如n位移位器所需晶體管數為2×n×n=2n2 (傳輸門部分采用CMOS實現),所帶來的功耗和芯片面積也會增加;(3)每一移位操作只需一根控制線為1,所以需輔以額外的譯碼單元。
3.1.2 樹狀結構(Tree Style)移位器
這種結構M位移位器所需的級數是log 2M每一級都由兩根信號線(shn和sh n#)控制數據的傳輸,數據在第i級要么移動2 i位或者不移動。樹狀移位器如圖3所示。

這種結構的優點是:(1)晶體管數目少,n位移器所需晶體管數目為2×n×log n(傳輸門部分采用CMOS實現),版圖面積小于矩陣移位器;(2)控制信號shN~sh0本身就是二進制表示,不需要額外的譯碼單元。缺點是:數據通路所需經過的開關管數目太多,M位移位器所需的級數是log 2M,因此導致延時太大。
3.2 矩陣-樹狀結構移位器
由上面的分析我們可以看出,如果所設計的處理器為16位以下CPU,那其移位器不管采用上述哪種方案都能達到要求,但當數據寬度到32位以上,從功耗,速度及版圖面積考慮以上方案的固有缺點就會顯得非常突出。在本設計中,移位寄存器的實際輸入為64位,為結合矩陣結構的優點(速度快、版圖規整)和樹狀結構的優點(晶體管數目少、譯碼簡單),我們在設計中采用矩陣-樹狀結構整個移位寄存器的是由雙總線輸入,即輸入64位,表1中列舉了不同級別比例的矩陣-樹狀結構所需晶體管數目(n1為tree的級數,n2為matrix的控制線,n3為matrix中用的晶體管數目)。經過綜合考慮,我們采用第2行的矩陣-樹狀級別比例,即矩陣部分最大能實現8位移位,樹狀部分最大能實現4位移位。

經過各方面綜合考慮,我們所設計的移位寄存器的前級為矩陣結構部分(輸入數據為64位,控制信號8位),由這一部分形成一36位的數據送入下一級樹狀結構(輸入數據為36位,控制信號2位)部分再完成剩余的4位移位,形成32位輸出數據。結構簡圖如圖4所示。

在這個結構中,后級的樹狀移位器最高實現3位移位。輸入的2bit信號為2進制碼,這兩位由移位計數器sh4~sh0直接將最低兩位送入(在后一節將介紹)。前級的矩陣結構完成64位輸入36位輸出,我們設64位數據輸入由Abus,Bbus提供,如圖5所示。每一小格代表4位數據。這64位數據送入矩陣移位器后,根據計數器的高三位sh4~sh2 進行譯碼對其進行4,8,12,16,20,24,28,32中的一種移位(對應8bits中的一位為高)。形成36位的數據輸出送入下級樹狀移位器以完成剩余位數的移位。36位數據輸出格式如圖6所示。其中COUNT表示總共移位數。


4 指令的預處理及移位類指令的實現
在我們設計的這片CPU中,需要對INTEL的 X86系列移位類指令進行兼容。因此移位寄存器單元需要在周圍譯碼和鎖存單元的配合下,要能在一個指令節拍內實現ROL,ROR,RCL,RCR, SHL,SHR,SAR,其中RCL,RCR實現了帶標志位C的移位(指令說明見文獻[4])。因此需由處理器的控制單元在每類移位指令移位之前進行指令的預處理。
4.1 移位寄存器單元總體結構
最終設計出的移位寄存器單元總體結構如圖7所示,其中其核心部分的矩陣-樹狀結構的移位寄存器就是使用上一節所描述的結構。記數器中的數據(sh4~sh0)在移位上一拍由Bbus寫入,并進行譯碼,其中低兩位(sh1,sh0)直接送樹狀結構移位部分,高三位(sh4,sh3,sh2)經過譯碼產生8位控制信號送入矩陣移位部分。Abus和Bbus輸入鎖存器能鎖存32位數據輸入,并根據不同指令的要求進行操作,對指令進行預處理。移位結果送ALU輸出鎖存器,并對CF寄存器進行設置。

4.2 指令的預處理
由于要對實現帶進位CF的移位并在移位操作后對CF進行設置,在一般情況下這需要CPU的控制單元提供多周期指令節拍來實現。在本設計中,將Abus和Bbus輸入鎖存器設計為能根據不同的指令實現清0和帶CF左移一位或右移一位的操作,以便為移位做好數據上的準備,使輸入數據的0~32位移位能在一個指令周期內完成。對不同的指令具體設置情況如圖8所示。圖中CF表示為進位標志位;len為操作數長度(如32位數據);n為移位數;DATA表示輸入鎖存輸出的數據為操作數據本身;0表示輸入鎖存輸出的數據為0;CF:DATA(-1)表示輸入鎖存輸出的數據為操作數帶CF右移一位;DATA(-1):CF表示輸入鎖存輸出的數據為操作數帶CF左移一位;SIGN_EXT表示輸入鎖存輸出的數據為操作數帶符號擴展。橫線下為移位前Abus和Bbus鎖存器中數據預處理完后的格式,橫線上方位移位完成后數據輸出及進位CF所處位置。
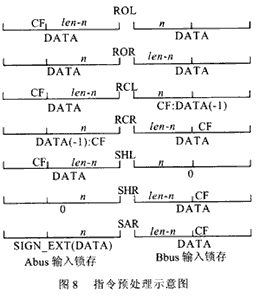
例:RCL AX ,CL指令
設AX=0001H , CL="3" , CF=1
Abus鎖存器輸出數據為操作數本0001H;
Bbus鎖存器輸出的數據為操作數帶CF右移一位為1000H;
在輸出中,CF在輸出結果的最左端為0。
5 驗證及結論
通過verilog的行為仿真及starsim的時序仿真顯示,性能完全符合要求。對比INTEL X86指令集中移位類指令標準執行周期為4~7個機器周期,本設計移位類指令平均執行時間為2個指令周期,因此大大提高了移位類指令執行效率。移位寄存器作為CPU中執行單元的專用硬件,其性能的好壞直接影響到CPU處理移位類指令的速度和效率。本文采用的矩陣-樹狀結構移位寄存器,配合指令預處理技術,能有效實現32位數據的移位操作,并兼容INTEL X86系列的所有移位類指令還可作為通用硬件方便地移植到其他指令級別的CPU設計之中。