
AVS(Audio Video Coding STandard)是由我國數字音視頻標準工作組制定的具有自主知識產權的第二代音視頻壓縮準。AVS實行1 元專利費用的原則,相比其它音視頻編解碼標準具有編碼效率高、專利費用低、授權模式簡單等優勢。AVS解碼器的結構復雜、運算量較大,要在嵌入式平臺上實現實時解碼具有較大難度。在對解碼器性能優化的過程中可以依據使用平臺對其進行匯編指令集的優化或者針對解碼器的關鍵算法模塊進行改良,以上方法對解碼器性能的提高均有一定作用,本文提出一種利用嵌入式平臺的L1P Cache高速緩沖功能實現處理器對程序代碼的高效率訪問的方法,從而達到提高AVS解碼器性能的目的。
1 高速緩存Cache的應用
目前越來越多的編解碼算法采用DSP的方式實現,隨著DSP芯片主頻的不斷攀升,存儲器的訪問速度日益成為系統性能提升的瓶頸。在現有的制造工藝下,片上存儲單元的增加將導致數據線負載電容的增加,影響到數據線上信號的開關時間,這意味著片上高速存儲單元的增加將是十分有限的。為了解決存儲器速度與CPU內核速度不匹配的問題,高性能的CPU普遍采用高速緩存(Cache)機制。
以TI的C64x DSP為例,存儲器系統由片內存儲器和片外存儲器兩部分組成。其中,片內存儲器采用兩級緩存結構,第1級L1距離DSP核最近,數據訪問速度最快,可以達到每秒600Mbyte,只能作為不能尋址的Cache使用,由相互獨立的L1P和L1D 組成。
L1P Cache是處理器訪問程序代碼的高速緩沖存儲器,大小為16 kbyte,采用直接映射方式,每行大小32byte;L1D Cache是處理器訪問數據的高速緩沖存儲器,大小為16 kbyte,采用2路映射,每行大小為64byte。第2級L2是一個統一的程序/數據空間,可以整體作為SRAM映射到存儲空間,也可以作為Cache和SRAM按比例的一種組合。L2與L1之間的數據交互速率為每秒300 Mbyte,L2與SDRAM之間的數據交換速率為每秒100 Mbyte。片外存儲器是第3級,一般由SDRAM構成。L1、L2和片外SDRAM構成了整個存儲器系統的層次結構。C64X的兩級緩存結構若能運用恰當,將能極大地提高程序性能。
根據圖1的三層次的存儲器系統, C64X讀取程序代碼時,先查看1級緩存L1,若L1已緩存了所需代碼,則直接從L1讀取;若L1沒有該代碼的緩存,則訪問2級緩存L2;若L2也沒有,則通過EMIF接口訪問外部SDRAM,把所需代碼從外部SDRAM拷貝到L2緩存區,再從L2緩存區拷貝到L1,最后由DSP內核取得。
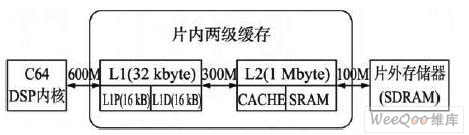
圖1 三層次的存儲器系統(圖中B代表byte)
研究表明,采用這種多級緩存的架構可以達到采用完全片上存儲器結構的系統約80%的執行效率。本文致力于更深入地研究Cache的機制,對算法的數據結構、處理流程以及程序結構等進行優化,以提高Cache的命中率,更有效地發揮Cache的作用,從而達到提高解碼器運行效率的目的。
2 基于Cache的視頻解碼算法實現
為了克服上述不足,本文通過更改視頻解碼算法的實現架構,充分利用Cache中L1P,減少CPU讀取程序代碼的缺失次數,提高解碼程序的執行效率。
在具體實施過程中,本文根據L1P的容量和程序中各個功能單元代碼的大小,將圖2中的功能單元分為四個模塊,每個模塊代碼大小均小于16 kbyte,各模塊所包含的功能單元為:模塊A,讀入一個宏塊;模塊B,熵解碼、反掃描、反量化、反變換;模塊C,重建;模塊D,環路濾波。
一個視頻宏塊只有遍歷這四個模塊之后才算最終完成解碼,各個模塊之間傳遞的中間數據如果放置在片外SDRAM中,勢必影響下一個模塊獲取數據的速度,如果數據放置在片內SRAM中,由于片內RAM空間有限不能存儲整幀數據。所以權衡考慮,每個模塊完成一個宏塊行(假設一幅圖像包含有M個宏塊行,每行有N個宏塊)的解碼后再交給下一個模塊處理,這樣既可以將中間數據放置在片內又可以充分利用L1P,減少各個模塊之間的代碼沖刷,直到M 個宏塊行全部處理完畢,這樣就得到一幀數據的解碼圖像。
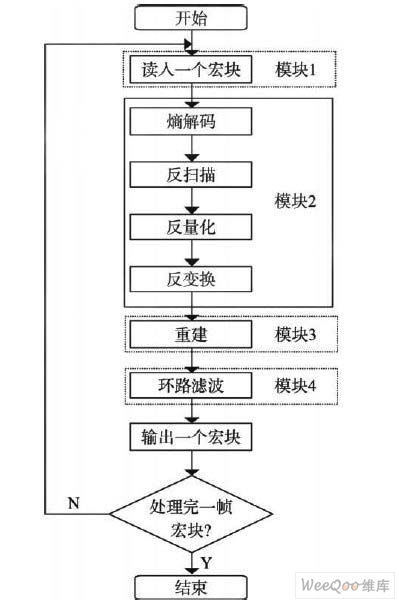
圖2 解碼算法流程
如圖3所示,本文以一個宏塊行為處理單位,在進行解碼時,首先執行模塊A將整個宏塊行讀入高圖3 處理一個宏塊行的新流程速緩存中,執行完畢模塊A后,讀入模塊B的代碼,該部分代碼將會沖掉模塊A 的代碼。執行完畢模塊B后,讀入模塊C的代碼,該部分代碼將會沖掉模塊B 的代碼。依此類推,當執行完畢模塊D后,再重復執行以對下一個宏塊行進行解碼。
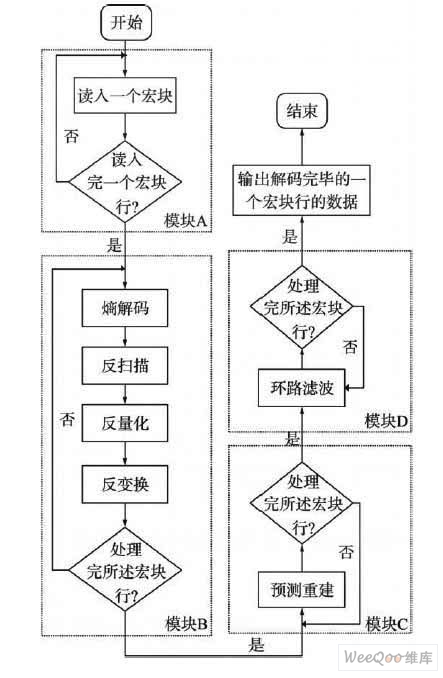
圖3 處理一個宏塊行的新流程
每個模塊在執行一個宏塊行的解碼過程中,會被反復執行N 次,在此期間程序代碼保留在L1P中不被沖刷,直到第二個模塊執行的時候第一個模塊的代碼才被沖刷。所以此方法解碼一個宏塊行才發生四次沖刷,完成一幀圖像的解碼共發生4 ×M 次代碼沖刷,較改進之前減少沖刷次數4 ×M ×(N - 1)。
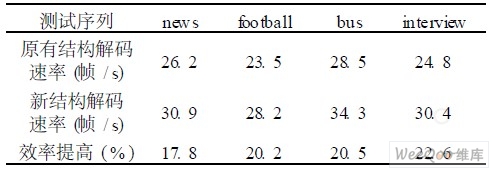
表1中的測試序列分辨率為720 ×576,調整結構后解碼速率均有不同程度的提高,通過對統計結果的平均得知,效率提高20%左右。
表1 實驗結果
3 結論
本文解碼器優化充分利用了處理器的程序Cache功能,模塊分配方式依據Cache大小而定,針對不同處理器的不同Cache, 可以有不同的模塊劃分方式,只需要保證每個模塊代碼量小于程序Cache容量即可。處理器對于數據的讀取同樣可以采用類似方法,以達到充分利用數據Cache的目的。此方法不僅可以應用于AVS解碼器,也可應用于AVS編碼器,還可以應用于與之擁有類似結構的H. 264、MPEG、VC1等編解碼算法。