
數字儀表結構簡單,使用方便,已廣泛應用于科學實驗和生產中。為了提高檢定效率、檢定精度,實現自動化檢定是十分必要的。由于數字儀表的檢定是一項大批量、重復性的檢測過程,其操作過程簡單、規范,外界環境要求不高,這為其實現檢定自動化提供了有利條件。近年來計算機視覺技術和數字圖像處理技術的不斷發展,為滿足上述要求提供了可能。利用攝像機完成表盤及背景圖像的采集,并將其轉換成數字信號,然后利用數字圖像處理技術實現關鍵操作,實現數字儀表的自動檢定,提高了檢定精度、生產效率、降低了生產成本。本文開發的儀表顯示值自動實時識別系統主要包括:圖像預處理、特征提取和數字識別3部分。其中數字識別是關鍵一環,主要采用了學習理論中的支持向量機方法。學習理論是一種研究有限樣本情況下機器學習性質和規律的理論。在這一理論下發展出的一種通用的模式分類器——支持向量機,由于與傳統的模式識別方法相比,具有推廣能力強,能保證全局最優等優點,這使得支持向量機技術在數字識別系統中有很好的應用前景,因而引起了國內外學者的極大興趣。支持向量機通過結構風險最小化準則和核函數方法,較好地解決了模式分類器復雜性與推廣性之間的矛盾,因而也引起了模式識別領域學者的極大關注。
1 儀表示值自動識別原理
儀表顯示值自動實時識別系統的流程:首先,由攝像頭獲取儀表顯示的視頻幀;然后,將視頻幀進行灰度變換,二值化得到二值圖像;再通過邊緣檢測,操作微分直方圖,計算表盤水平和垂直投影,進行峰谷分析定位出數字區域,并切分出單個數字的二值圖像;對單個數字的圖像進行特征提取,得到一組特征;最后,將特征送入識別器進行識別。
1.1 預處理
數字儀表在檢定過程中,首先要定位表盤區域,然后確定數字位置。攝像頭提取圖像后,經過灰度變換(見圖1)和二值化(見圖2),其效果將對后續的數字切分和特征提取產生直接的影響,其中二值化是圖像預處理的關鍵環節,在實際應用中受室內燈光及儀表屏幕自身亮度等因素影響,圖像中往往存在灰度分布不均和灰度突變的情況。本文采用了OTSU算法,根據最大方差二值化獲得良好的二值圖像,這里主要為了提取表盤區域。通過標識連通區域,連通區域的外接矩形,然后根據外接矩形的長與寬定位數字儀表的顯示區域。本文采用了一個8連通區域提取算法。首先按照一定的標號規則掃描圖像,得到一定數量的連通區域;然后針對同一區域內標號不一致的情況進行處理,即得到最終處理結果。

1.2 數字分割
表盤區域分割之后,繼續分割數字區域。在實際應用中,攝像頭是固定的,數字的顯示區域在圖像中的位置、大小等是基本相似的。本文根據數字儀表顯示屏幕的特點,采用投影法找到顯示屏的邊框。圖像中數字區域的準確定位分割是實現儀表顯示值識別的重要前提。在表盤的二值圖內,先通過邊緣檢測,利用微分直方圖進行數字分割,圖3為水平投影后的直方圖。

經過水平投影將圖像分割成上、中、下3部分。對中部數字區域的二值圖像從上到下逐行掃描;獲取到圖像的水平投影圖。利用行間間隔形成的水平投影間隙,即可將各數字行分割開來,如圖4所示,然后提取中部截圖,再對中部數字區域做垂直投影,如圖5所示,計算峰谷可以將單個數字分割出來。字切割是從行切分后,得到的圖像中將每一個數字分割出來,利用每行字符的垂直投影中字符之間的間隙即可將各個數字分割出來。

1.3 特征提取
由于數字具有明顯的局部結構特征,因此本文采用一種非對稱分塊統計特征,作為表征數字的特征向量。方法如下:
(1)應用otsu方法將分割出的數字圖像二值化,然后將圖像歸一化為70×50大小;
(2)將圖片等分為35塊,每塊子圖為10×10大小,按式(1)計算每一塊中背景點的分布特征;

式中:p(m,n)為10×10子圖中m行n列像素灰度值,前景點為255,背景點為0。
(3)將每一塊子圖的背景點統計特征作為一維特征向量,構造35維向量[a1 a2 … a34 a35]作為支持向量機的輸入特征向量。
1.4 數字識別
基于支持向量機的數字識別支持向量機(Support Vector Machines,SVM)基于結構風險最小化準則工作,能在訓練誤差和分類器容量間達到較好平衡,因而具有更好的性能,在模式識別領域有著廣泛的應用。對于兩類模式識別問題,假設給定n個樣本作為訓練集:
![]()
這里yi=+1或-1,要找到一個最優超平面,使訓練集中的點距離分類面盡可能的遠,也就是使M=2/‖ω‖最大的分類面就是最優分類面。對于線性可分的情況,要找到最優超平面:
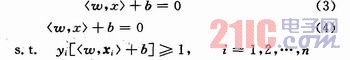
即求解下面的二次規劃問題:
![]()
此二次規劃問題,可用Lagrange乘子法把式(5)化成其對偶形式:
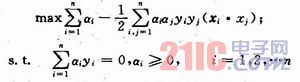
設[a1 a2 … a3]為二次優化問題的解,可以證明解中只有小部分ai不為0,稱對應的xi為支持向量,ai是對應的Lagrange系數,b是常數(閾值)。于是最優超平面方程為:
![]()
最優超平面的分類規則為:
![]()
對于線性不可分情,在條件式(5)中引入非負松弛變量ξi,原約束條件改為:
![]()
相應的目標函數改為:
![]()
最優分類面的對偶問題改為:
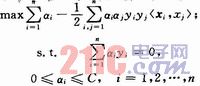
若ai>0,稱相應的xi為支持向量(Support Vector)。更進一步,若O
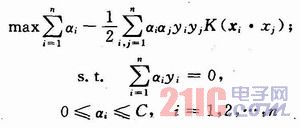
找出的支持向量充分描述了整個訓練數據集的特征,使得對SV集的線性分類等價于對整個數據集的分類,檢測流程圖如圖6。所示。

1.5 實驗結果與分析
實驗中選取了3組典型的樣本,每組樣本數200個,在PC機上進行了試驗,結果如表1所示。每個樣本有6或5個數字,其中3或4個是表示小時和分鐘,2個表示秒鐘。
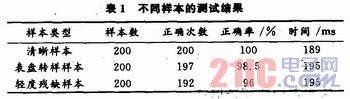
從表1可以看出,在二值化較好,數字清晰的情況下,識別率達到了100%,對有輕微點狀噪聲和輕微斷痕的樣本,識別率也很高,但對存在數字殘缺的樣本,識別率有所下降。就識別時間而言,整屏數字(6或5個數字)的識跗時間小于200 ms,明顯低于儀表數字的最快變化時間1 000 ms。
2 結語
主要研究了數字式儀表的自動判讀方法,為儀表盤上的儀表實現自動識別打下基礎。首先對采集到的數字式儀表進行預處理,主要包括圖像灰度化、二值化、噪聲消除等。參考現有的數字識別算法,本文主要采用垂直投影法來分割各個字符,然后對分割后的每個字符提取分塊統計特征。最后用SVM訓練樣本實現相應數字字符識別,最終判讀出數字儀表的讀數。該方法算法簡單,實時性高,可靠性好,是一種比較理想且具有一定應用價值的識別算法。